随着信息技术的不断发展,文本压缩技术的重要性日益显现。大型文本压缩基准的提出,既是对计算机压缩能力的挑战,也是自然语言处理(NLP)领域迈向智能化的一次重要尝试。本文全面解析大型文本压缩基准的理论基础、人工智能属性以及相关技术难点,揭示其在推动语言模型和人工智能研究中的核心地位。 文本压缩不仅仅是数据存储的需求,更深层次代表着对语言本质的理解和建模。研究表明,完美的文本压缩等同于解决自然语言处理中诸多复杂问题,如语音识别、光学字符识别(OCR)和语言翻译等。这些任务被称为“AI-hard”,意即解决其中一个问题即可相当于全面攻克文本相关的人工智能难题。
换言之,文本压缩的理想状态近似于通过图灵测试的机器智能表现。尽管图灵测试至今尚无人类无法识别的机器通过,但这一理论关联明确指出文本压缩的深刻AI意义。 大量文本压缩算法依赖于对自然语言字符串概率分布P(s)的精准模型。香农定理指出,最优编码长度与字符串的概率密切相关,理论上若已知P(s),高效的算术编码可以逼近最优。然而自然语言的复杂性使得明确计算字符串概率极为困难。人类语言天生隐含概率分布,体现于我们自然的言语交流之中。
现代文本压缩器的核心任务即为构建或自动学习高效且准确的语言概率模型。 压缩问题与机器智能有着深刻的数学联系。Hutter在2000年证明了最优理性行为体的决策策略等价于压缩其观察到的数据——即寻找能生成相应观察序列的最短程序。这一观点佐证了奥卡姆剃刀原则,最简单的解释往往是最优解。这类理论进一步揭示了压缩不仅仅是技术挑战,更是智能本质的体现和验证。 为何选择维基百科文本作为压缩基准?维基百科内容高质量、丰富且具有开放版权,涵盖多领域知识,极适合作为训练和测试大规模语言模型的理想语料库。
尽管维基百科包含一些XML标记和用户ID等非纯文本数据,这些复杂元素实际上能帮助模型更全面地理解文档结构和语义特征,提升语言理解能力。此外,维基百科庞大的数据量满足了构建和评估高端压缩算法的规模需求,同时保证研究的公开透明与可复现。 为何选用英语文本作为测试语言?英语是互联网最广泛使用的语言,语料库丰富且结构成熟。尽管多语言语料库能促进算法的泛化和语言迁移能力,英语作为单一语言的选择为算法训练提供了良好平衡,避免了资源分散和复杂度爆炸问题。该选择也便利了研究者集中精力优化算法核心,不被多语言处理的额外挑战干扰。 大型文本压缩基准设定规模于1GB,是基于多方面考量。
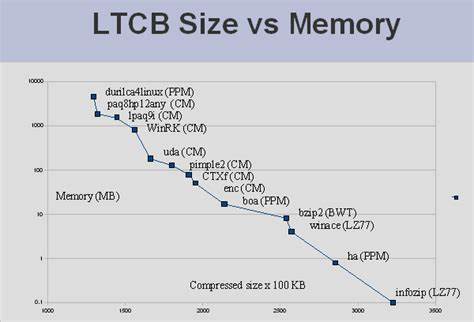
首先,现实中存储和内存限制决定了模型和压缩算法的资源使用不可能无限扩展。1GB的数据规模,既具备挑战性,足以测试算法的学习与建模能力,又能保证模型在硬件资源允许范围内运作。其次,这一规模亦接近人类一生中语言信息的处理量级,符合模拟和理解人类语言智能的目标。 文本压缩之所以显得“难”,不仅技术上涉及复杂的概率计算和上下文分析,背后更隐含着语言的深层AI问题。人类语言表达丰富且富含隐喻、多义等语义复杂性,机器要在不依赖庞大词典和规则的条件下实现高效压缩,需要具备极强的学习与泛化能力。现有流行的算法诸如LZ系列、Burrows-Wheeler变换和预测部分匹配(PPM)、上下文混合(CM)等,虽在一定程度上优化了模式识别和编码过程,但仍未达到人类对语言结构的深入理解。
相比人类,计算机在编码实现上具有决定性优势。人类很难依据概率分布设计稳定且唯一对应的编码方案,而计算机算法可精准执行算术编码并保证解码准确。人类则擅长建模和概率估计,但在压缩实现的具体映射上表现不佳。这个“建模+编码”的双重过程,揭示了人工智能实现中的计算机与人类能力互补特性。 为何不采用有损压缩作为文本基准?有损压缩在视觉和声音领域表现出色,模仿人类感知特点实现有效信息舍弃,压缩效率高。然而文本信息较少包含冗余噪音,并且意义传递对细节高度敏感,有损压缩容易丢弃关键语义,影响文本的准确表达和理解。
另外,有损文本压缩结果的评价主观性强,难以通过客观量化指标实现公平比较。相比之下,基于无损压缩的基准更能保证评价结果科学、客观且可重复。 如何评价压缩算法性能?压缩比显然是最直观的指标,体现了压缩算法对语料统计和语义结构建模能力。复杂的语言模型还可通过困惑度(perplexity)等指标间接反映对语言概率分布的拟合效果。现实应用中,语言模型的优劣通常与语音识别误码率、OCR字符错误率密切相关,通过压缩比的提升也能带来这些任务性能改善。 尽管致力于大规模无监督语言模型的研究已近数十年,当前成果依然难以完全复制人类语言的丰富语境感知和逻辑推理能力。
大型文本压缩基准的设立,旨在激励更深层次的算法创新,通过对真实语料的大规模建模,推动计算机智能在自然语言理解方面实现重大突破。 文本压缩基准的规则中特别包含了对解压缩程序大小的计算。其目的在于避免“作弊”行为,即仅通过包含文本完整信息的庞大解压程序实现形式上的压缩,违背了压缩的本意。通过将解压缩器体积纳入评价,使算法必须同时优化解码复杂度和压缩率,实现真正意义上的高效模型构建。 当前主流的无损压缩技术中,基于统计和上下文的模型依然占据优势地位。诸如PPM和上下文混合技术通过结合多种历史上下文信息预测下一个字符概率,实现了精细的语言序列建模。
尽管如此,更高层次的语义和语法分析尚未广泛融入主流压缩算法,成为未来突破的重点方向。 此外,语义分析技术如潜在语义分析(LSA)通过矩阵分解揭示词汇之间的深层关联,理论上可帮助改进上下文预测,挖掘文本更丰富的内在结构。但将此类离线语义模型整合到实时压缩算法中依然存在巨大的技术难关。真正意义上的智能压缩应能跨越表层词汇、句法,理解语义,甚至知识推理,实现更近似人类思维的编码效率。 大型文本压缩基准的提出推动了NLP领域对语言模型评价标准的统一。相比传统的人工智能判定如图灵测试,其精准量化且可自动执行的特征为算法研发者带来了极大便利,也带动了包括统计机器学习、深度学习在内的多种人工智能路径的发展。
它引导研究者关注长距离依赖、上下文语义连贯性以及多模态融合等关键问题。 展望未来,随着计算资源的增长和算法的进步,预计大型文本压缩的性能将逐渐接近人类语言模型的熵极限。达成这一目标不仅仅意味着压缩技术的突破,更将是通向真正智能自然语言理解和生成的重要里程碑。此类技术进步将促进智能问答、自动翻译、文本生成、语音识别等领域革命性的发展。 综上所述,针对文本的压缩基准不仅仅是一个技术挑战,更是人工智能研究的一个重要方向。它涉及语言学、信息论、计算机科学及认知科学等多学科交叉,体现了理解和模拟人类语言智能的综合努力。
大型文本压缩基准正是连接理论与应用的桥梁,是未来智能语言处理系统的基石和风向标。