在现代软件开发中,随着项目规模日益庞大,如何高效管理和理解海量代码成为一个亟需解决的问题。代码不仅仅是静态的文本,它们蕴含着复杂的结构和语义信息。传统的代码查看或简单文本搜索方式难以满足开发者对精准定位和分析的需求。为此,基于抽象语法树的代码解析技术逐渐兴起,而Tree-sitter作为其中的佼佼者,凭借高性能及语言支持的广泛性,带来了革命性的编码体验。Code-Chopper便是基于Tree-sitter构建的一个创新库,它提供了按语义层面拆分代码块的功能,极大提升代码搜索与分析的效率和准确性。Code-Chopper是一个用TypeScript开发的开源库,致力于将多语言代码语法分析与结构化拆分相结合,帮助开发者从函数、类、方法乃至变量声明等语义边界切分代码。
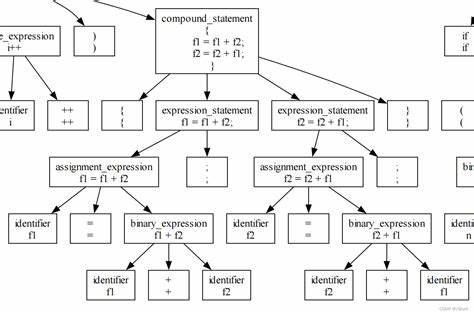
不同于传统的按行拆分或者正则表达式匹配方式,Tree-sitter根据源代码生成具体语法树(Concrete Syntax Tree,简称CST),并能够精确识别代码的语法结构,使得Code-Chopper能够按照实际编程语法含义,而非文本片段,将代码分割成有意义的模块化块。Code-Chopper支持包括TypeScript、JavaScript、Python、Ruby、Java、C、C++等十余种编程语言,满足跨语言项目管理和多样化代码库的需求。其灵活的配置功能允许用户自定义拆分粒度,甚至可以针对特定代码块类型进行筛选,确保提取内容精准且高效,大幅减少无关信息的干扰。通过Code-Chopper,用户可以实现对代码库的自动文档生成,将函数和类的定义以及注释内容整合为易于理解的文档材料。同时,结合现代大型语言模型(LLM)工具,拆分后的代码块可用于智能代码补全、摘要、错误定位以及安全扫描等。具体功能方面,Code-Chopper的核心包括ParserFactory,用于创建和管理针对不同编程语言的Tree-sitter解析器,在提高解析速度和资源复用的同时保证多语言兼容性。
文件操作模块提供了读取文件、递归解析目录以及基于代码字符串的处理接口,方便大规模代码库的批量拆分与处理。拆分结果则以BoundaryChunk为单位,携带代码内容、起止位置、代码边界类型、名称及文档注释信息等丰富元数据,为后续搜索和分析提供充分上下文。在实际使用上,用户只需通过npm或bun进行安装,随后利用ParserFactory创建相应语言解析器,即可调用读取文件或目录的接口,自动完成语义拆分。配置选项中允许添加过滤函数和排除目录,便于灵活定制拆分规则和范围。该工具不仅适合代码搜索引擎后端用作索引生成,还可集成到IDE插件和持续集成流水线,助力开发者实现智能代码导航和快速定位。Code-Chopper采用MIT开源协议发布,开发者社区持续贡献语言支持和特性改进,使得功能日趋完善。
它部分借鉴了ushironoko/gistdex项目的设计理念,同时在性能和灵活性上有所突破。对于科研人员和代码治理专家而言,Code-Chopper的语义拆分能力有助于大规模代码分析、模式识别和漏洞检测等自动化工作提供坚实基础。未来,随着Tree-sitter生态不断发展,Code-Chopper也将支持更多新兴语言和复杂语法结构,进一步拓宽其应用深度。总的来说,Code-Chopper通过结合Tree-sitter的准确代码语法树解析能力,实现多语言、语义清晰的代码块提取,极大提升代码搜索、重构和文档自动化的效率。它弥补了传统基于文本处理手段的不足,使得开发者和工具链能够更智能、更快速地理解和处理庞大复杂的代码仓库。对于追求高效代码管理和智能分析的团队来说,Code-Chopper无疑是一款值得掌握的重要利器。
。