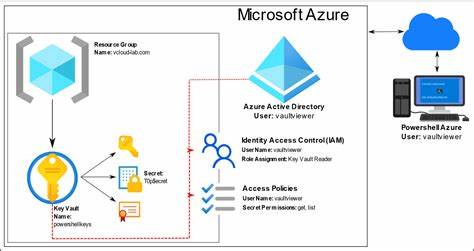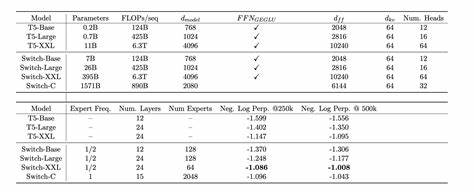
随着人工智能和机器学习技术的迅猛发展,计算需求正以前所未有的速度增长。尤其是在深度学习和大规模神经网络训练中,浮点运算的数量已达到前所未有的水平。要满足未来复杂模型的计算需求,机器学习编译器必须实现规模上的飞跃,支持万亿万次(10的24次方)浮点运算,从而推动人工智能迈入新纪元。 机器学习编译器是连接高阶算法与底层硬件执行的关键桥梁,它将复杂的计算图转化为高效可执行的代码。随着模型复杂度的增长,传统编译器面临着诸多挑战,诸如代码规模膨胀、内存带宽限制、并行度管理以及硬件异构性的适配等问题。实现面向万亿万次浮点运算的规模,要求编译器设计在优化算法、资源调度和硬件兼容性方面进行全方位的创新。
扩展机器学习编译器以支持如此庞大的运算量,首先需要重新考量数据流和计算图的管理方式。传统的静态编译模式难以应对动态变化的计算需求,因此采用动态编译与自适应优化技术成为趋势。通过实时分析运行时的信息,编译器能够动态调整计算策略,优化内存使用,提升并行计算效率。同时,利用异构计算资源合理分配任务,减少瓶颈,显著提高整体性能。 另外,硬件层面的进步也为编译器扩展提供了基础。以GPU、TPU等专用加速器为代表的新一代硬件架构具备更高的并行处理能力和更低的延迟,这使得管理几乎无限的浮点运算成为可能。
编译器必须深入理解并配合这些硬件特性的调度算法,最大化算力利用率。例如,通过优化张量操作的内存访问模式,减少数据传输成本,进一步提升浮点运算效率。 在软件架构方面,模块化设计和可扩展性是关键。现代机器学习编译器往往采用层次化结构,以支持插件式的优化组件和多种硬件后端。这样的结构不仅便于维护和扩充,还能灵活适应不同的应用场景和模型需求。与此同时,开源生态的建设也极大地加速了技术迭代,促使编译器能够快速集成最新科研成果,应对日益增长的运算负载。
此外,面对万亿万次浮点运算的复杂度,编译器在稳定性和容错性方面也提出了更高要求。大规模计算过程中不可避免地出现硬件故障或数据异常,如何保证计算结果的正确性和系统的稳定运行,成为设计的重点。实现自动检测与恢复机制,加强错误传播的控制,使编译器能够在极端条件下依然保持高效且可靠的执行表现。 人工智能的应用领域极其广泛,无论是自然语言处理、计算机视觉还是科学计算,均对高性能计算提出了更严苛的要求。机器学习编译器的扩展直接影响着模型训练周期和推理速度,进而决定了应用的实际可行性和市场竞争力。能够支持万亿万次浮点运算的编译器不仅加速科研进展,也为产业升级提供坚实技术支撑。
不过,技术的进步也带来了新的能源消耗和生态压力。如何在追求极致性能的同时优化能效比,成为设计者绕不过去的课题。优化算法的能效意识增加,采用智能调度和功耗管理策略,推动可持续发展的计算环境,正是未来机器学习编译器发展的重要方向。 未来,随着量子计算和边缘计算的发展,机器学习编译器还需适应更多元的计算范式和硬件形态。跨平台兼容性、安全性加固以及对新兴技术的支持能力,将成为评价编译器优劣的重要标准。通过持续创新和开放合作,迈向支持万亿万次浮点运算的智能编译器时代,将大大推动人工智能的普及和应用深化。
总而言之,实现万亿万次浮点运算规模的机器学习编译器,是人工智能底层技术突破的关键枢纽。结合动态编译技术、硬件协同优化、模块化设计和能效管理等多方面的创新,编译器正在为超大规模机器学习计算铺设坚实基础。未来,随着相关技术的不断成熟,机器学习编译器将在推动智慧社会和智能产业发展中发挥不可替代的重要作用。