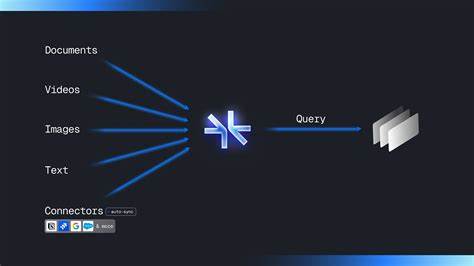
随着人工智能技术的不断进步,大型语言模型(LLM, Large Language Models)在自然语言处理领域展现出巨大的潜力和广泛的应用场景。诸如OpenAI的ChatGPT、谷歌的Bard、Anthropic的Claude等不同的LLM平台不断涌现,推动了智能对话、内容生成、知识管理等多个领域的创新。然而,随着多种LLM工具的普及,用户面临一个共同的挑战——记忆的碎片化。用户在一个平台中积累的个人知识、对话历史和偏好信息往往无法无缝迁移或共享到另一平台,造成了信息孤岛和重复输入,影响使用体验。Supermemory-mcp正是在这一背景下应运而生。作为一款基于Supermemory API构建的开源工具,其使命是打破现有大型语言模型间的记忆壁垒,打造一个通用且统一的记忆中枢,帮助用户实现跨不同LLM应用的记忆共享。
Supermemory-mcp的出现为AI记忆管理注入了新活力,打开了更加灵活智能的信息沉淀和调用方式。 Supermemory-mcp最核心的价值在于构建“Universal Memory MCP”(通用记忆多客户端平台),它让用户在ChatGPT中的记忆可以自由流转并应用于其他任何支持的LLM平台。传统情况下,用户的记忆数据往往绑定在特定应用内,无法有效导出或接入其他服务。Supermemory-mcp通过构建统一接口,以API驱动的方式存储与调用记忆,实现了“写一次,处处可用”的目标。这种能力大幅提升了用户跨平台的效率和连贯体验,比如同样的偏好设置、历史对话内容、专属知识库等在不同聊天机器人中都可以立即调用,就像拥有一个全智能的“个人大脑”。 值得注意的是,Supermemory-mcp具有极其简洁的使用体验。
用户无需进行繁杂的注册步骤,也不受传统登录和付费的限制,只需要一条命令就能完成配置,便可快速接入其内置的通用记忆服务。这种免登录、永久免费使用的设计,降低了普通用户和开发者的试错成本与部署门槛。对于企业用户或技术爱好者来说,Supermemory-mcp也支持自托管模式,只需从官方平台获取API密钥并配置即可搭建私有记忆服务器,既保障了数据隐私,也给予更高的灵活性和扩展性。 在技术层面,Supermemory-mcp基于现代云基础架构和分布式系统技术,实现了高并发、低延迟的记忆数据访问能力。其背后的Supermemory API充分利用了云端存储和检索技术,能够快速索引和调取用户历史信息,支持多种数据类型和自定义属性,满足不同LLM应用对记忆的多样化需求。此外,项目代码使用TypeScript开发,兼顾了前端与后端的执行效率和代码安全,使整个系统架构稳健且易于维护。
Supermemory-mcp的推出还意味着未来语言模型的协同发展将不再局限于单一平台,开启了记忆互联互通的新篇章。用户可以根据具体场景灵活切换不同LLM,而不是被某一应用锁定,推动AI生态体系向更加开放和包容的方向迈进。长远来看,激活这种通用记忆的共享机制对于提升各类智能助手的个性化服务能力也有关键意义。通过累积和融合各平台的知识积淀,语言模型能够更精准地理解用户需求,提供更智能、更贴合的交互体验。 该项目的示范视频和具体操作步骤公布于其官方网站mcp.supermemory.ai,用户仅需访问即能体验全流程,进一步验证其实用性与便捷性。社区的反响同样热烈,截至目前,Supermemory-mcp已在GitHub获得超过1200颗星标,显示出开发者和用户间对通用记忆解决方案的强烈需求。
总的来说,Supermemory-mcp的诞生填补了当前多大型语言模型应用中记忆隔离的空白,将无缝记忆共享变成可能。它不仅极大提升了用户数据资产的价值,也助推了AI多模态、多平台协作的未来形态。随着更多LLM产品接入Supermemory生态,通用记忆概念必将成为智能人机交互的重要基石。未来,我们期待Supermemory-mcp在持续迭代中完善功能,拓展更多应用场景,让“记忆无界限,智能共连接”真正实现,从而带动整个人工智能领域进入一个更高效、更人性化的新阶段。









