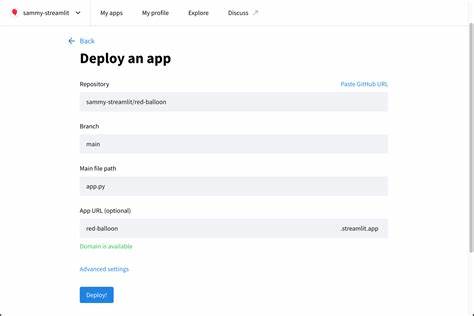
随着数据驱动决策成为企业核心竞争力,越来越多的工程和数据团队需要快速构建并分享可视化工具和数据仪表盘。Streamlit作为一款简便易用的Python应用框架,以其快速开发和直观交互深受欢迎。然而在实际应用中,如何合理且高效地部署内部Streamlit应用成为团队面临的关键问题。本文将结合来自技术社区和企业实践的经验,深入剖析团队部署Streamlit应用的常见方法、鉴权和网络安全模型、团队规模影响,以及遇到的挑战和应对策略,为相关从业人员提供系统化的参考。企业为何选择Streamlit内部部署Streamlit在数据科学领域的迅速崛起,源于其简单的开发流程,无需繁复前端知识即可实现功能丰富的可视化界面,使非技术人员也能轻松理解数据结果。其开箱即用的特质非常适合中小规模的企业内部数据团队快速搭建工具。
然而,Streamlit本质上更多被设计为数据探索和快速原型工具,对于大规模、并发访问、复杂权限控制的生产场景有一定局限。因此,企业需权衡业务需求与技术实现,确定最佳部署策略。主流部署方案解析公有云服务提供了多种便捷托管环境,谷歌云平台(GCP)中的Cloud Run因其无服务器扩展特性获得青睐,能够自动分配计算资源,适应访问流量波动。同时,AWS的Elastic Beanstalk和容器服务也被部分团队选用以实现弹性伸缩。部分组织还利用Streamlit Community Cloud快速分享轻量级应用,但该服务限制多且对内网应用场景支持不足。近年来,Streamlit与数据平台如Snowflake集成逐渐增多,直接在数据仓库环境中嵌入Streamlit应用,简化数据流转,提高安全性。
除此之外,许多团队选择自建私有服务器,通过Docker容器方式部署,保障数据完全控制权同时结合团队内部已有的身份认证系统。团队规模与访问量对部署影响不同企业规模和用户需求决定了应用的规模和部署复杂度。小型团队内部应用通常用户数在十几到数十人之间,使用简单的基本鉴权或内网VPN即可满足安全需求;这类场景对资源消耗和应用响应性能要求相对较低,运维成本也较易控制。但当规模扩大至上百甚至上千用户时,单机部署的弊端凸显,应用访问延迟增加,运维复杂。此时多节点集群部署、负载均衡和持续集成成为重点。选择支持横向扩展的云方案或容器编排技术(如Kubernetes)能够有效提升稳定性和弹性处理能力。
身份认证与网络安全构建安全可信的访问体系是内部部署的核心。基础的身份认证方法包括基本认证(用户名与密码),但安全性有限,仅适合非敏感应用或内网环境。更多企业倾向集成单点登录(SSO),通过公司已有的OAuth或者SAML协议,实现统一身份管理,提高用户体验并加强审计合规。部分对安全要求较高的团队会部署专用VPN,将访问流量限定在受信网络范围内,防止数据外泄。此外,结合多因素认证和访问权限分级,保障敏感数据免受未授权访问。常见痛点及优化建议成本控制是许多非公开应用部门面临的重点。
云托管方案虽铺设便捷,却常常因为长时间运行与不断扩容导致费用不断攀升。合理配置应用的开启与休眠策略,避免资源空闲浪费,是重要手段。技术驱动体验(DX)方面,Streamlit的执行流模型被部分开发者诟病。其线性脚本运行逻辑在复杂交互和页面状态管理场景存在局限,导致开发时调试和维护成本提升。深入理解其数据流与事件触发机制,以及结合状态保持工具(如Session State)能够缓解部分问题。合规要求日趋严格的环境下,部分企业必须自建环境,避免外包云平台引发的合规风险。
此外,日志审计、访问监控以及加密通信需配套完善。未来部署若重头开始的建议经验丰富者建议,从架构设计初期即考虑伸缩性和安全模型,避免后期只能依赖手动扩容。采用微服务思想,将复杂应用拆分成功能独立的组件,可提升维护效率。选择支持容器化和自动化部署的方案能为团队释放更多精力专注业务,而非基础设置。总结Streamlit作为数据和工程团队内部应用开发的利器,在部署方面呈现出多元化发展趋势。公有云无服务器方案、私有服务器自建、与数据平台联合部署,各有优劣和适用场景。
团队规模、安全需求和运维能力深刻影响选型。通过妥善设计身份鉴权和网络边界控制,有效降低泄露风险与维护成本。理解Streamlit内部执行机制对优化用户体验尤为关键。总的来看,未来内部Streamlit应用部署的方向将更加注重自动化管理、弹性扩展及安全合规,帮助企业实现更敏捷的数据应用落地和业务赋能。