随着大数据技术的不断进步,数据处理系统的性能优化成为行业关注的焦点。TPC-DS基准测试作为衡量大数据查询引擎综合性能的重要工具,受到了广泛关注。本文主要围绕最新版本的Trino 476、Spark 4.0.0和Hive 4搭载MR3 2.1的表现进行深入评测,探讨三者在速度、资源利用以及容错机制等方面的差异,揭示MPP架构与MapReduce架构的本质特点及其在现代大数据领域的应用价值。 在数据仓库和大规模数据分析场景中,性能优异的SQL-on-Hadoop解决方案尤为关键。Trino作为典型的MPP(大规模并行处理)引擎,凭借其推送式数据传输模型和高效执行计划实现了极致的查询速度。Spark 4.0.0则是基于MapReduce思想的计算框架,虽然支持内存计算优化,但在部分复杂查询场景仍存在性能瓶颈。
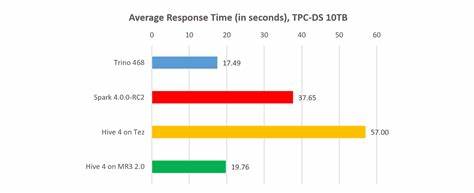
Hive 4结合了MR3 2.1这一新兴架构,通过融合MapReduce的容错机制与内存计算带来的性能提升,展现了兼顾速度与稳定性的显著优势。 根据基于10TB规模因子的TPC-DS基准测试,三大系统在顺序执行与并发执行场景均完成了全部查询,体现出良好的系统健壮性。顺序测试中,Trino依旧维持最快速度,完成99条TPC-DS查询仅用约4245秒,Hive on MR3紧随其后,耗时约4299秒,而Spark则显著落后,总时间超过1.5万秒左右。值得注意的是,Hive on MR3在新版本中性能提升明显,相较于之前的测试快约13%,显示出其架构优化带来的实质性进步。 平均响应时间的表现同样突出,Trino以约17.46秒的平均查询响应时间保持领先,Hive on MR3以17.84秒紧随其后,而Spark的响应时间则达到了38.24秒。分析认为,Trino的优势在于其推送式数据处理架构,能够最大限度地减少数据移动延迟,但也存在数据准确性上的罕见问题,如测试中第23号查询出现错误计算。
并发测试则使Hive on MR3展现出更为坚实的实力,在不同并发级别(10、20、40)下,其最长执行时间均低于Trino和Spark,特别是在40并发的情况下,Hive on MR3的执行速度比Trino快25%,比Spark快60%。这说明Hive on MR3在多用户、多任务环境下的负载均衡与资源分配更为合理,整体系统表现更加平稳可靠。 评价三种系统架构的根本差异,有助于理解实力背后的技术逻辑。MPP架构以推送模型为核心,将中间数据主动传递给消费者节点,实现高并行度和低延迟的查询处理,但其固有缺陷是容错机制困难,通常依赖重跑整个查询来应付节点故障。Trino作为MPP代表,在性能方面表现卓越,但准确性和容错能力仍需持续改进。相比之下,MapReduce架构则采用拉模型,所有中间数据写入磁盘,由消费者主动拉取,这一机制天然支持容错,能保证即使部分节点失效,任务仍能稳定运行,但引入了额外的磁盘I/O和网络开销,影响查询速度。
以Spark和Hive为代表的基于MapReduce的系统长期被认为在运行速度上难以超越MPP引擎。 MR3作为一种基于MapReduce的架构创新,成功弥补了传统MapReduce性能不足,尤其在Hive 4环境下表现突出。MR3优化了中间数据处理,借鉴了MPP系统中以内存存储和快速交换数据的思想,减轻了磁盘I/O瓶颈,同时保留了完整容错机制。结果表明,MR3兼具MPP的高效性能和MapReduce的稳定可靠特性,实现了业内罕见的平衡点。 MR3的设计使得Hive not only can run traditional MapReduce workflows but also embrace modern computational demands such as containerization and Kubernetes orchestration. This flexibility allows it to operate stably in Hadoop-based clusters, standalone environments, and cloud-native infrastructures, broadening its adoption scenarios and future-proofing its capabilities. 综上所述,通过对最新版本的Trino 476、Spark 4.0.0、以及Hive 4 on MR3 2.1的详细性能评测,显示了当下主流大数据查询引擎在TPC-DS标准下的真实表现。尽管Trino依然保持领先,但Hive on MR3以更优异的并发处理能力和进步显著的响应时间,展现出极具竞争力的实力。
Spark作为成熟且通用的计算框架,虽在某些复杂查询中表现劣势,但仍具备丰富生态系统优势和多样化应用场景。 从架构视角看,MPP架构和MapReduce架构各擅胜场,前者速度快但容错难,后者容错强但性能受限。MR3的出现及其在Hive中的实践,为MapReduce架构注入了活力,证明性能与容错并非无法兼得。未来大数据系统应继续向着融合两者优势、提升资源利用率与用户体验的方向发展。 作为数据工程师、架构师或企业决策者,针对具体业务需求结合实际环境选择合适的查询引擎至关重要。希望借助此次基于TPC-DS的深入对比分析,能够帮助读者更好地理解不同系统的性能特点与技术原理,从而做出明智选择,推动数据驱动决策与数字化转型不断向前迈进。
。