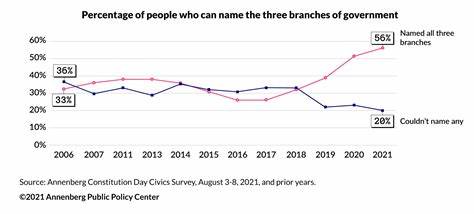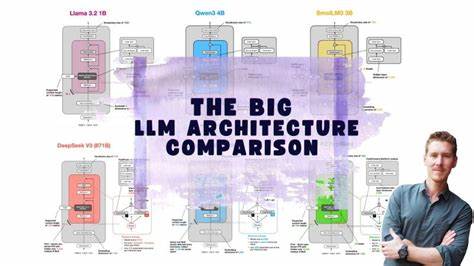
近年来,随着人工智能技术的快速发展,大型语言模型(Large Language Models,简称LLM)成为自然语言处理领域的研究热点。大型语言模型以其强大的生成能力和语言理解能力,广泛应用于文本生成、机器翻译、智能问答等多个领域。市场上涌现出多款具备卓越性能的LLM架构,不同模型在设计哲学、技术路线、训练方法以及应用效果上各具特色。深入剖析这些架构之间的异同,有助于开发者、研究人员以及行业从业者更好地理解模型潜力,优化应用方案。 本文将围绕当前主流大型语言模型架构进行系统性对比,涵盖模型结构设计、训练数据、计算资源需求、推理速度、迁移能力和应用落地等多个维度,为读者提供权威全面的参考。 Transformer架构作为现代大规模语言模型的核心基础,引领了多代模型的发展。
无论是GPT系列、BERT系列还是近期的Flan和PaLM,均基于Transformer中的自注意力机制实现多层堆叠,以捕捉上下文依赖关系。不同模型在结构设计方面存在细节调整,如双向编码与单向生成的区别、注意力机制的改进、多任务训练策略融合等,这些变化直接影响模型的语言理解深度和生成质量。 GPT(Generative Pre-trained Transformer)系列通过单向Transformer解码器架构,实现了高效的语言生成能力。其最大优势在于利用海量无监督文本数据进行预训练,随后通过微调完成具体任务,展示出强大的通用性。GPT-3作为代表性版本,拥有1750亿参数,能有效处理复杂的上下文理解和多样化的文本生成需求。相比之下,BERT(Bidirectional Encoder Representations from Transformers)采用双向编码器结构,专注于语言理解能力,尤其擅长文本分类、问答匹配等任务。
其通过遮蔽语言模型(Masked Language Model)和下一句预测任务进行预训练,显著提升了理解句内和句间关系的能力。 此外,近年来涌现的混合架构也颇具代表性,如T5模型将多种NLP任务统一格式化为文本到文本的转换任务,整合编码器和解码器优势,实现了多任务学习的统一架构。另一类如PaLM则通过扩展模型规模及优化训练数据质量,挑战极限计算能力,进一步推动模型在多语言处理和推理推断的表现。 针对计算资源及推理速度,不同架构也呈现出多样性。超大规模模型通常依赖强大的分布式训练系统与高效的并行计算策略,且通常伴随较高的推理延迟和硬件门槛,这限制了其在资源受限环境下的应用。相比之下,轻量化模型如DistilBERT、TinyBERT通过知识蒸馏和模型剪枝技术,在保持较好性能的同时,显著降低了参数数量和计算需求,适合边缘设备和实时应用场景。
迁移学习能力是衡量大型语言模型实用价值的重要指标。多模态融合、领域适配和跨任务泛化能力不断提升,使得模型不仅仅局限于单一语言处理,而能扩展到视觉、语音及跨领域知识应用。模型训练过程中引入的提示学习和少样本学习技术,有效缓解了数据稀缺问题,推动LLM向更广泛的实际应用迈进。 在实际应用中,选择适合的LLM架构需结合具体需求、硬件条件和使用场景权衡。对于需要高质量文本生成与对话系统,GPT类模型往往表现突出;而需要精确语言理解与信息抽取的业务,则可优先考虑BERT及其衍生模型。综合性任务和多模态要求则可选择T5、PaLM等最新架构。
此外,随着开源生态的日益丰富,诸如OpenAI GPT、Google BERT系列、Meta的LLaMA等模型均已开源,极大地推动了研究创新和产业应用。利用开源模型进行二次开发和微调,已成为行业发展的主流路径,有力促进了大型语言模型技术的普及与优化。 总体来看,大型语言模型架构正处于不断迭代和创新的关键时期。多样的技术路线和架构设计促进了模型能力的提升,也带来更高的计算门槛和复杂度挑战。未来,如何在保持模型性能的同时实现更高效、更绿色的计算,以及更灵活的跨模态与跨任务应用,将是整个领域亟待攻克的重要课题。深入理解不同架构的技术特点和应用优势,对推动大型语言模型在各行业落地和普及具有重要意义。
。