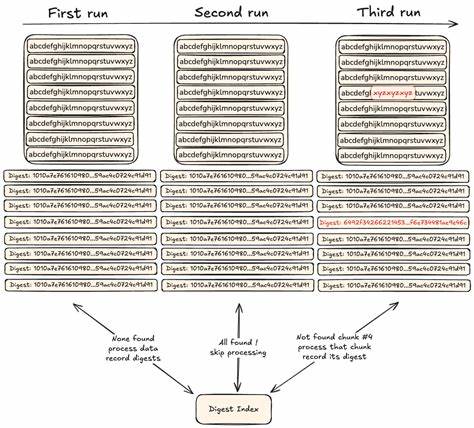
在当今数据爆炸式增长的时代,数据冗余成为了现代信息系统面临的巨大挑战。无论是企业级备份系统、云存储服务,还是实时数据同步和分布式数据库,重复数据的存在往往导致计算和存储资源的浪费,延长数据传输时间,增加系统负担,进而影响用户体验和成本控制。如何高效地识别并消除重复数据,已成为技术进步的重要方向。Go-CDC-chunkers作为一款基于内容定义分块(CDC)技术的高性能Go语言开源库,正是针对此痛点而生,提供了一套兼具速度与准确性的解决方案。 Go-CDC-chunkers由Plakar Korp团队开发,采用了先进的CDC分块算法,使数据被划分为可变大小、内容感知的块,这种划分方式能够抵抗数据偏移和局部修改带来的挑战。传统的固定大小分块在数据发生微小变化时,往往导致后续所有分块内容都发生偏移,无法有效重用之前的分块,影响重复数据删除效果。
而内容定义分块技术通过动态计算数据切点,大幅提升了系统的容错性和灵活性,使得即使数据中间插入、删除或修改了部分内容,大多数其他分块依旧能够被正确识别和复用。 Go-CDC-chunkers尤其优化了FastCDC算法,FastCDC基于Gear滚动哈希,简化并加速了传统CDC算法中的滑动窗口计算,极大提升了分块速度。FastCDC通过位掩码和哈希值的组合,快速判定切点位置,既避免了过小或过大的块带来的性能问题,也保证了块大小分布的均衡。通过这种方法,Go-CDC-chunkers在处理大规模数据时展现出了惊人的吞吐率,远超多数传统分块库,变革了数据分块的效率瓶颈。 除了纯粹的分块算法优化,Go-CDC-chunkers还创新性地引入了Keyed CDC模式,即通过密钥驱动的Gear表构建,不同于公开固定的Gear表,Keyed CDC使用加密哈希生成密钥化的Gear表,使得切点分布对于未持有密钥者不可预测。这种机制兼顾了数据切点的隐私保护,防止潜在攻击者通过分析切片边界推断文件内容和结构,为安全敏感型应用场景带来了新的保障层。
Go-CDC-chunkers不仅关注性能,设计时也极力兼顾内存占用和易用性。其简洁统一的接口允许开发者快速集成至各种数据流处理管道,无论是批处理任务还是流式数据处理,都能灵活适配。只需简单几行代码,即可完成复杂的内容定义分块操作,极大降低了技术门槛,使开发者能将更多精力聚焦于核心业务逻辑层面。 从应用维度看,Go-CDC-chunkers的优势尤为显著。备份与恢复系统通过内容定义分块加重删,能够最大限度地减少存储重复数据,节省存储成本和备份窗口时间。同步工具利用其对数据偏移的高容忍性,实现了高速增量同步,提升用户体验并降低网络带宽需求。
分布式存储系统则借助该技术维护数据块唯一性,简化数据一致性和复制策略,有效提高存取效率。与此同时,CI/CD缓存、日志存储、消息队列等领域同样受益于高效去重带来的资源释放和系统优化。 除了去重,Go-CDC-chunkers还能为差异编码和变更追踪提供基础支撑,增强系统对数据版本变化的感知能力。通过块级粒度的变更识别,开发者可以构建更为智能的数据处理流程,轻松实现增量传输和在线编辑协作等功能。得益于开源社区的活跃贡献,Go-CDC-chunkers已支持多种拓展算法,如JumpCondition优化版及UltraCDC等,不断引入前沿技术,保持其在分块与去重领域的技术领先地位。 相比传统基于文件或固定块的去重技术,内容定义分块带来的显著优势在于其高度的灵活性和稳定性。
即便面对文件重命名、局部编辑、数据插入等复杂变动,它依然能保证大部分数据块保持不变,从而实现跨时间和空间的高效去重。Go-CDC-chunkers凭借极致的性能与易用性,使得这一先进技术更容易被广泛应用,助力企业和开发者实现数据管理的智能化升级。 纵观整个数字时代的数据浪潮,重复数据问题的有效解决无疑能为信息系统节省巨额成本,提升体系运算速度和用户体验。作为一款开放源代码、面向未来的工具,Go-CDC-chunkers不仅响应了行业需求,更引领了内容定义分块技术的实践标准。它的出现不仅给开发者提供了强大的技术武器,也昭示着数据去重技术迈入了全新纪元。 未来,随着数据量的持续增长和应用场景的日益多样,Go-CDC-chunkers及其背后的内容定义分块技术将迎来更多创新和拓展。
如何结合机器学习优化分块策略、如何支持更多加密与隐私保护机制、如何实现更高并发和分布式协作,将是推动其进一步发展的关键方向。与此同时,社区的持续参与和企业用户的广泛反馈,将为该项目注入更多活力与可能。 总的来看,Go-CDC-chunkers不仅仅是一款简单的数据分块库,而是一套完整的高效重复数据消除解决方案。它通过结合先进的算法设计、极致的性能优化以及安全隐私的深度考量,为现代数据系统提供了不可或缺的技术支持。无论是企业级大数据管理,还是轻量级应用数据同步,Go-CDC-chunkers都展现出了强大的适应力和扩展潜能,为构建更加敏捷、智能和绿色的数据生态奠定了坚实基础。