随着人工智能和机器学习的迅猛发展,神经网络作为其中关键的技术基础,正逐渐成为解决复杂问题的利器。从图像识别、自然语言处理到自动驾驶和医疗诊断,神经网络的应用范围覆盖了现代科技的各个角落。然而,为什么我们需要神经网络?它们是如何实现学习的?特别是反向传播算法在其中扮演着怎样的角色?本文将深入探讨这些问题,帮助读者全面了解神经网络的本质和其学习原理。首先,我们需要理解传统计算方法为何难以处理复杂的模式识别问题。传统算法依赖于明确的规则和逻辑,难以适应数据中隐含的复杂关系。大规模非线性、多维数据的处理需求超出了传统编程的范畴。
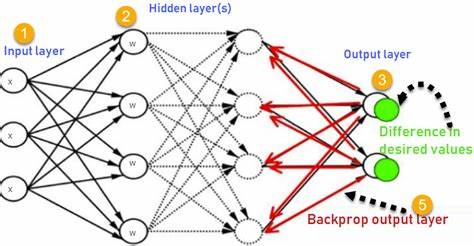
而神经网络通过模拟人类大脑神经元的结构,能够以分布式的方式对信息进行处理。这种结构使得神经网络能够捕获数据中的非线性特征和复杂模式,实现从数据中自动学习抽象表达。神经网络的基本单元是神经元,每个神经元接收来自上一层的输入信号,通过加权和处理后传递给下一层。多个神经元构成层,网络层与层之间的连接权重决定信息传递的强弱,这些权重是网络学习的关键参数。学习过程即为调整权重,以提升网络对输入数据的预测准确性。神经网络之所以强大,关键在于其能够通过经验数据进行训练,自动发现输入与输出的映射关系。
训练目标通常是最小化实际输出与期望输出之间的误差,这就涉及到误差反向传播机制。反向传播算法是神经网络学习的核心,是一种高效的梯度计算方法。它利用链式法则将输出层的误差信息逐层传递至输入层,从而计算每个权重对最终误差的贡献,指导权重的调整方向和幅度。反向传播的实现使得多层神经网络的训练变得可行,极大提升了深度学习的实际应用价值。在反向传播过程中,网络首先进行前向传播,即输入通过层层处理生成预测输出。随后,计算预测结果与真实标签之间的损失,损失函数用以衡量误差大小。
接着,损失通过反向传播被传递回每一层,根据梯度下降算法调整权重参数,逐步降低误差。通过不断迭代训练,神经网络权重趋于稳定,网络性能达到最佳。这一过程体现了神经网络的自适应性,即在面对不同任务和数据时,能够通过训练不断优化性能。神经网络的设计也不断进化,从最初的感知器模型发展为多层前馈神经网络、卷积神经网络和循环神经网络等多样结构,满足不同类型数据的处理需求。卷积神经网络特别擅长图像识别,它通过局部连接和权重共享减少参数量,提高训练效率和效果。而循环神经网络则善于处理序列数据,例如语音、文字等,能够捕捉时间维度上的动态信息。
此外,针对反向传播的优化研究也在不断推进。例如,引入正则化技术避免过拟合现象,使用不同的激活函数提升非线性表达能力,以及采用先进的优化器如Adam加速收敛速度。尽管神经网络和反向传播技术取得了巨大成功,但依然面临挑战。网络结构的可解释性较低,训练过程对超参数敏感,且计算资源需求较高。未来研究方向将聚焦提升模型透明度、优化结构设计和降低算力消耗。总之,神经网络作为人工智能技术的基石,凭借其卓越的自学习能力和强大的表达能力,推动了诸多领域的变革。
理解其学习原理及反向传播算法,不仅有助于深入掌握机器学习技术,也为未来创新应用奠定坚实基础。面对日益复杂的现实世界问题,神经网络依然是我们破解数据秘密、实现智能突破的重要利器。