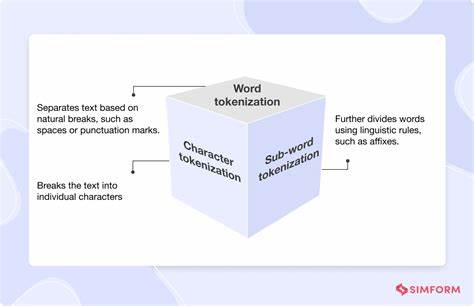
随着人工智能技术的飞速发展,语言模型在自然语言处理领域扮演着越来越重要的角色。分词作为文本预处理的关键步骤,直接影响到模型的理解能力和生成效果。长期以来,主流分词方法追求确定性和唯一性,即为每段文本映射一个“规范”的分词序列。然而,最新的研究发现,语言模型对所谓的非规范化分词表现出惊人的适应性和鲁棒性,这一发现为语言模型的灵活性和实际应用开辟了新的方向。传统上,分词器采用固定的词典和算法,将文本自动切分成词或子词单元,从而构建利于模型学习的输入序列。大多数模型训练时,都基于一种确定的规范分词方式。
也就是说,训练数据中的文本会统一按照单一的规则被切分,模型习惯并优化于此种输入。然而,现实世界的语言环境远比训练环境复杂,存在大量拼写错误、方言变体以及非标准表达,导致文本无法严格匹配规范分词。更进一步,同一句话完全可以对应多种不同但合理的分词序列,这些非规范分词在训练中未曾出现或极少出现,传统观点认为这会极大干扰模型表现。近日,来自多名研究人员的开创性工作打破了这一传统认知。他们以指令微调(instruction-tuning)后的语言模型为对象,分别测试了模型面对随机抽样的非规范分词和字符级分词时的表现。令人惊讶的是,这些经过指令微调的模型在多达二十个不同的基准任务上,仍能保持原始性能的90%以上,部分情况甚至高达93.4%。
尤其在字符级分词这种极端的非规范切分方式下,模型依然能达到90.8%的原性能水准。随着模型实力的增强,这种对非规范分词的鲁棒性趋势愈加明显,而当分词方式偏离规范程度越大时,鲁棒性略有下降。研究还深入挖掘了非规范分词在特定任务中的优势。例如,当任务涉及字符串操作或代码理解时,采用字符级分词能提高多达14%的性能表现;在大数运算任务中,采用数字从右向左分组的非传统分词策略,更是将结果提升了33%。这意味着,非规范分词不仅不会削弱模型的能力,反而能在特定场景下激发出潜在优势。为何语言模型对非规范分词表现出如此卓越的适应性?研究团队发现这一现象的根源在于指令微调阶段。
未经指令微调的基础模型面对非规范分词时,会将其视作文本中的拼写错误并试图模仿这些“错误”,从而导致输出混乱无序。相反,经过指令微调的模型则更专注于理解潜在语义和上下文,生成合理且流畅的回应,而非简单模仿输入中的瑕疵。这种微调过程极大提升了模型对输入格式多样性的包容度和抽象理解能力。这个发现颠覆了过去对语言模型与分词器关系的传统认知。长期以来,业界普遍认为模型性能高度依赖规范的分词方法,分词器的选择和设计几乎决定了模型的表现极限。然而,本研究证明模型并非牢牢绑定于训练时使用的分词规则,而是在实际推理中具备对不同分词策略的灵活适应能力。
这为未来语言模型的设计和应用带来诸多启示。首先,在实际应用中,模型能够应对非标准输入大大增强了其适用范围,无需苦心设计一套完美无缺的分词策略即可实现高质量的文本理解与生成。其次,研究鼓励人们探索更多创新的分词方案,不再拘泥于传统规则,而是根据任务需求和文本特点灵活调整分词策略,甚至临时以不同方式分词以提升性能。此外,指令微调作为提升模型鲁棒性的重要手段,其地位和价值愈发凸显。未来的语言模型训练或许将更加强调这一阶段以实现更优表现和更广泛的容错性。总而言之,语言模型面对非规范分词展现出的强大适应性和表现力,标志着自然语言处理技术进入了更成熟和灵活的阶段。
随着相关研究深入和实践推广,我们有理由期待这些发现会在智能问答、文本生成、代码理解、语音识别等多样化应用领域掀起新变革,推动人机交互迈上新的台阶。