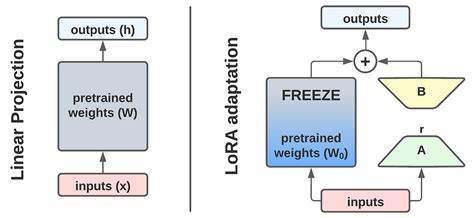
近年来,随着人工智能技术的迅猛发展,AI模型的训练和推理需求飞速攀升,促使计算硬件正经历根本性变革。在这一背景下,AMD作为半导体行业的领军企业,积极布局AI市场,以领先的GPU加速器和基于架构创新的计算方案,深度参与这场技术革命。2025年,AMD发布全新的机架式AI计算平台——Helios,融合最新一代GPU、CPU及高性能网络组件,旨在为大型AI集群提供强大算力和卓越能效,引领AI硬件进入“机架级”时代。 AMD的Helios平台不仅是一套单纯的硬件组合,更是AMD打造的完整AI生态系统核心。通过整合新一代Instinct MI350X系列GPU、第五代EPYC Turin处理器和高性能的Pollara 400 AI NIC,AMD为企业客户提供端到端的机架级AI解决方案,便于构建大规模、高密度、可高效扩展的深度学习集群。Helios的平台设计紧跟行业对速度和效率的双重需求,提升整体能效比,降低部署与运维复杂度,助力数据中心实现更高效的AI工作负载处理。
核心驱动力之一是AMD Instinct MI350系列GPU,这款基于最新第四代CDNA架构的加速器采用了尖端的3D混合体堆叠技术,拥有高达1850亿晶体管和八个计算单元芯片(XCD),每个包含32个计算单元,显著提升矩阵运算的吞吐能力。相比前代产品,MI350凭借对FP6和FP4低精度数值格式的原生支持,在AI推理中展现出极高的效率,能够在2.4GHz高频率下实现最高5拍浮点运算的运算性能,远超竞争对手。高达288GB的HBM3E高速内存保证了数据交互的流畅无阻,大宽带达到8TB/s,极大缩短数据访问瓶颈。 MI350系列针对不同散热环境提供了两款型号:液冷版本的MI355X和空冷版本的MI350X,分别满足极致性能和灵活部署的需求。这些产品的功率分别达到1400瓦和1000瓦,但其高性能输出与功耗比得到客户一致认可。AMD宣称,基于MI355X的系统在AI性能与成本上具备明显优势,特别是在单位算力的电费和硬件成本方面,能提供比NVIDIA(GA200系列)约40%的token处理成本优势。
软件方面,AMD以开放且高效的ROCm平台持续赋能硬件性能的最大化。最新发布的ROCm 7版本针对CDNA4架构进行了深度优化,不仅显著提升了训练和推理速度,还重点强化了企业级AI集群的管理和生命周期支持。AMD致力于实现“Day-0”支持,确保主流深度学习框架如PyTorch和ONNX Runtime能够在新硬件面世时迅速兼容,极大缩短客户产品的开发周期与上线时间。ROCm的多节点分布式功能和GPU直连访问特性进一步助力用户构建大规模训练环境,推动下一代AI计算的生态蓬勃发展。 除了核心计算与软件,网络性能在AI集群中同样关键。AMD通过旗下收购的Pensando公司推出的Pollara 400 AI NIC,补全了机架级AI方案中的最后一块拼图。
作为400G以太网卡,Pollara 400具备高度可编程和灵活扩展性,支持PCIe 6.0与业界领先的Ultra Accelerator Link(UAL)技术,为超大规模GPU互联提供强大带宽和低延时保障。该NIC的设计基于TSMC先进工艺打造,能够满足快速扩容和多租户环境下的网络隔离需求,契合未来多样化AI应用场景。 重塑AI计算生态,AMD还描绘了中长期技术蓝图。2026年推出的MI400 GPU以“CDNA Next”架构为基础,计划带来20拍浮点(FP8)级别性能,配备432GB的下代HBM4内存,并强化Ultra Accelerator Link以支持从现有8卡扩展到1024卡的规模化计算能力。这款GPU将成为Helios机架的核心,配合第六代EPYC“Venice”处理器和全新Vulcano 800G以太网卡,形成强大的软硬一体化平台。 AMD全面推进机架式AI硬件,从芯片架构设计、散热方案,到集群互联协议和软件支持,展现出对AI行业未来的深刻洞察和战略布局。
公司目标是在2030年前实现与MI300X相比达到20倍的机架能效提升,并配合算法和软件优化,最终实现100倍的整体能源效率革命。这一愿景不仅体现了对环境可持续性的承诺,也抓住了AI算力飞跃带来的商业机遇。 显而易见,随着新一代硬件加速器和网络技术不断涌现,企业级AI计算的格局正在重新定义。AMD Helios机架方案将为云计算服务商、高性能计算中心,以及科研机构提供极具竞争力的选择,为AI训练和推理提供强劲底层支持。面对当今和未来日益复杂的AI模型需求,AMD的多元化战略和技术创新将成为市场的重要推手,为全球AI产业打开更广阔的发展空间。随着市场对机架级AI解决方案的关注度提升,AMD通过Helios项目展示出其持续进军高性能计算领域的决心和实力,势必在未来AI硬件版图中占据越来越关键的位置。
。