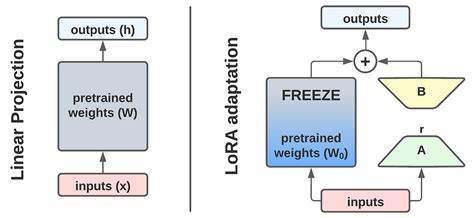
随着人工智能技术的快速发展,大型语言模型(LLM)在众多领域展现出强大能力,然而如何快速、灵活地将这些基础模型适应不同具体任务,始终是学术界和工业界面临的重要挑战。传统的微调方法虽能提升模型性能,但通常耗时长、计算资源需求大,且每个新任务都需独立训练,限制了模型个性化和动态调整的可能性。针对这一瓶颈,Text-to-LoRA(T2L)的出现无疑是一次重要变革,它通过自然语言指令驱动,能够实现对大型语言模型的即时适配,彻底颠覆了以往复杂、繁琐的调优流程。Text-to-LoRA作为一种基于超网络(Hypernetwork)结构的创新方案,能够生成针对特定任务的LoRA(低秩适配器)参数,仅需一次前向传播即可完成,省时省力。相比传统方法需要收集大量标注数据和反复迭代训练,T2L只需输入简单的文本描述,即可自动构建出完整结构的适配器嵌入到基础模型中,极大提升了模型定制的可访问性和灵活性。Text-to-LoRA的核心设计理念在于将任务描述、目标模型模块(如查询投影层)及层级索引三者编码成一个联合输入向量,通过该向量驱动超网络生成对应适配器权重。
这种巧妙的输入组合不仅保证了生成参数的结构完整,还实现了多层多模块的批量生成,与训练时的高效性相辅相成。为了让模型具备更强的泛化能力,研究团队提出了两种训练策略:一种是重建预训练好的多种LoRA适配器,完成压缩和知识整合,使得T2L拥有丰富的参数表达能力;另一种则是监督微调(SFT),直接在多样化下游任务数据上训练模型,使其学会根据不同文本指令生成高效的适配器,从而实现真正意义上的零样本任务泛化。实验结果显示,采用监督微调训练的T2L模型在面对未知新任务时,表现优于传统多任务LoRA微调和少样本上下文学习。这表明文本驱动的生成策略不仅继承了LoRA调优的效率优势,更突破了以往在相似任务语义与权重空间不一致所带来的限制。更为难得的是,T2L还能通过改变任务描述的表述方式,有效引导模型沿着不同推理路径实现符合预期的正确回答,体现了优秀的人机交互潜力。可视化分析进一步证明,T2L在隐含空间中形成了清晰的任务集群,语义相近的任务适配权重靠得更近,说明模型内部学习到了一种语义驱动的参数生成规律。
这种规律不但为参数高效压缩提供支持,也为后续扩展适配器设计提供了理论基础。尽管如此,研究者回顾中也坦诚,当前零样本适配的表现仍与专门任务训练的“最优适配器”存在一定差距,同时适配质量受任务描述清晰度显著影响,模糊或偏离实际意图的文本简报会导致效果下降。此外,训练阶段借助了GPT-4o-mini等大型语言模型生成任务描述,这在一定程度上说明了T2L性能与训练数据质量存在内在关联,未来或许能探索更自主的生成体系。展望未来,Text-to-LoRA的潜力仍有巨大拓展空间。其能否实现小型基础模型向更大规模模型间的迁移学习?是否能超越生成LoRA参数,直接调节模型激活函数实现更高效的适应?这些问题引发了学术界对通用模型适配框架的深层思考。Text-to-LoRA所带来的即时、按需、以文本为导向的适配方式,正在悄然推动人工智能进入一个更加动态且可定制的时代。
它不仅降低了技术门槛,还使得非专业用户能够通过简单对话实现对复杂模型的个性化控制。未来,或许定制AI不再依赖繁琐代码,而是通过直白自然语言轻松完成。商业领域面对此技术也充满期待,即嵌入式、动态可调节的大型语言模型将在智能客服、个性化助理、内容生成等多个方向极大释放价值。总而言之,Text-to-LoRA以其独特的技术优势和深远的应用潜力,代表了模型适应方法的一次质的飞跃。它把模型调优从计算密集型、经验依赖型转向智能化、自动化和人性化,为未来智能系统的发展奠定了坚实基础。随着研究和产业不断深入,Text-to-LoRA极有可能成为下一代人工智能模型核心组件,推动智能技术真正走进日常生活的方方面面。
。