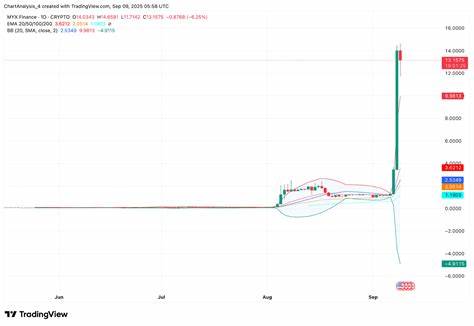
在机器学习和人工智能领域,模型的训练过程通常被视为提升性能的核心环节。然而,随着技术的不断发展,后期训练(Post-Training)作为一种重要的补充手段,逐渐引起了业界的广泛关注。Post-Training不仅能够在模型完成初步训练之后,进一步优化其表现,还能有效解决在实际应用中遇到的多种问题。本文将全面解析Post-Training的概念、技术方法及其实际应用,帮助读者深刻理解这项技术在现代AI系统中的价值。Post-Training是指在初始模型训练完成后,针对特定任务或环境,采用额外的数据、调整技术和训练策略来细化和优化模型性能的过程。相较于传统的训练流程,Post-Training更注重在实际使用场景中的适应性和灵活性,旨在弥补模型初期训练中可能存在的不足,从而提升整体表现。
众所周知,模型训练过程中面临的挑战诸多,包括数据分布偏差、过拟合问题、模型泛化能力不足等。通过Post-Training,可以基于新的数据集或特定的数据分布,进行有针对性的微调和调整,使得模型在面对不同应用场景时表现更加出色。具备良好Post-Training策略的模型,通常在准确率、鲁棒性和运算效率等方面均有显著提升。Post-Training的优势首先体现在提升模型的泛化能力。训练阶段使用的数据往往有限且具有一定的先验假设,当模型应用于多样化的现实环境时,这些假设可能不再成立。通过后期训练,模型能够快速适应新的数据分布,提高其识别和预测的准确性,增强系统的稳定性和适用范围。
此外,Post-Training还能有效降低模型参数量和计算负担。许多大型深度学习模型在初始训练时,需要庞大的计算资源和存储空间。通过后期训练中的模型剪枝、量化等技术,可以实现模型的轻量化,使其更适合边缘计算或移动设备的部署,推动AI应用的普及和推广。应用层面,Post-Training涵盖了多种操作手法,包括微调(fine-tuning)、知识蒸馏(knowledge distillation)、模型剪枝(model pruning)、量化(quantization)以及迁移学习(transfer learning)等多种技术组合。微调是Post-Training中最为常见的方式,借助预训练模型的权重,针对目标任务进行二次训练,使模型更贴合具体需求。知识蒸馏则通过教师模型指导学生模型学习,实现高效的模型压缩;模型剪枝跟量化则能显著减少模型计算资源的消耗,提高运行速度。
随着深度学习模型复杂度和规模的增加,Post-Training在各行各业的应用愈加广泛。无论是自动驾驶中的图像识别、医疗影像诊断中的辅助分析,还是语音识别和自然语言处理领域,后期训练技术均发挥着不可替代的作用。例如,在智能语音助手的开发中,通过Post-Training对特定口音和方言进行适配,使得语音识别系统的准确率大幅提升,用户体验得以优化。面对未来,Post-Training的发展趋势也呈现出多样化和技术深度提升的态势。首先,自动化Post-Training流程的兴起将降低对专家手动干预的依赖,通过AutoML(自动机器学习)等工具,实现模型调优的智能化和高效化。此外,结合联邦学习和隐私保护技术,Post-Training还能在确保数据安全的前提下,促进不同机构间协作训练,丰富模型的适用场景和数据多样性。
总而言之,Post-Training作为连接初始训练和实际应用的重要桥梁,对于模型性能的提升和应用效果的优化至关重要。它不仅弥补了传统训练的不足,还为AI系统带来了更强的适应性和实用性。随着人工智能技术的不断进步,深入理解并灵活运用Post-Training技术,将成为推动智能系统创新和落地的关键动力。 。