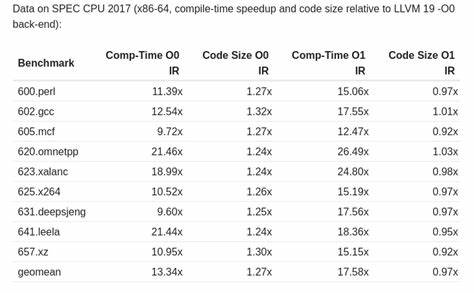
在现代技术发展的浪潮中,分布式系统作为支撑大规模应用和服务的核心架构,受到了越来越多的关注。随着业务规模的不断扩大,系统的复杂度和负载也随之增加,然而一个普遍而有趣的现象是,规模的扩展通常不会带来性能的线性提升,反而会导致系统整体速度变慢。Goto 2024大会上,这一现象再次成为业内专家热议的焦点,众多演讲展示了规模增长为何成为分布式系统性能瓶颈的根源。要深刻理解“规模导致分布式系统变慢”这一课题,首先必须解析分布式系统的工作机制及其面临的具体挑战。分布式系统通过将任务分散到多个节点上协同处理,以实现高吞吐量和高可用性。然而,节点数量的增加也带来了协调和通信的复杂度提升。
系统中的每个节点并非孤立运行,节点之间需要进行状态同步、数据复制和一致性保证。随着节点数量攀升,通信开销及一致性维护的难度急剧增加,进一步引发延迟和资源竞争的问题。Goto 2024上的专家指出,分布式系统延迟的根本原因在于网络通信的不可避免性。即使网络技术持续进步,节点间通信的时间开销无法消除,尤其是在跨数据中心和跨地理区域的场景中更为明显。网络延迟直接限制了系统对事务处理速度的提升,造成了扩展过程中性能的瓶颈。此外,随着系统规模的扩大,故障的概率随之提高。
分布式系统设计通常采用冗余副本与故障检测机制保障高可用性,但这也引入了复杂的容错协议和错误恢复路径。容错机制的复杂度提升,必然拖慢整体响应速度,使得系统在保证可靠性的同时牺牲了一定的性能。资源竞争和瓶颈也是规模扩张导致性能下降的重要因素。不同节点在处理过程中可能争抢有限的硬件资源,如CPU、内存和网络带宽。随着节点数目增加,资源分配机制的复杂度显著上升,调度不合理或负载不均都会造成部分节点成为性能的短板,从而拖累全局效率。规模增长还对分布式系统的一致性维护提出了更高要求。
CAP定理告诉我们,在分布式环境下,一致性、可用性和分区容忍性三者不能同时完美满足。系统规模越大,网络分区发生的概率也越高,保证强一致性的代价也变得更大。为了权衡一致性与性能,设计者不得不在可用性和延迟之间做出妥协,这直接影响了系统的响应速度。今天,微服务架构和云原生技术的兴起,让分布式系统的大规模部署更加普遍。Goto 2024的视频内容中,讲者深入剖析了几种常见的优化方案,以应对规模扩展带来的性能挑战。例如,通过减少节点之间的通信次数和数据交换量,采用更轻量级的协议,以及利用异步处理和事件驱动架构来缓解实时同步压力,都能有效降低系统延迟。
另外,分区策略和负载均衡算法的优化也非常重要。合理地划分数据和任务,使得节点间负载均衡,避免某个节点成为瓶颈,对整体性能提升有显著作用。动态调整策略和自适应调度机制的应用,进一步增强系统在负载波动时的稳定性和响应速度。除了技术层面的优化,团队协作和运维策略也起到关键作用。系统规模扩大意味着运维复杂度和出错概率提高,如何通过自动化监控、故障预警和快速恢复机制保证系统的高可用性,是保证性能不被规模拖累的必要条件。Goto 2024的讨论还强调了对设计理念的反思。
程式化思维和架构设计的灵活性对分布式系统的扩展能力起着决定性作用。只有在设计之初就充分考虑规模带来的复杂性,采用模块化、可插拔的设计模式,才能在实际运行中有效克服性能瓶颈。总结来看,规模是分布式系统性能提升的双刃剑,一方面带来计算能力和服务容量的提升,另一方面也带来了通信延迟、故障概率和资源竞争的挑战。Goto 2024上的专家们通过理论解析和实践案例,阐明了这些影响的具体机理,并提出了针对性的解决方案。未来,随着技术进步和新兴算法的引入,分布式系统的扩展能力将继续提升,但对规模与性能关系的深入理解和精准把控,将是系统设计人员必须面对的核心课题。对于企业和技术团队而言,理解规模带来的复杂性并采取科学合理的架构策略,不仅有助于提升系统整体性能,也为实现业务的持续稳健发展奠定坚实基础。
。