LLVM作为现代编译技术的重要里程碑,其灵活的中间表示和强大的后端优化能力一直被业界推崇。然而,LLVM在无优化等级(-O0)下的编译速度却长期困扰着开发者,成为提升编译效率的突破口。近期,TPDE团队开源的TPDE-LLVM后端引起了巨大关注,因其在-0优化级别下实现10到20倍的编译速度提升,同时保持了接近LLVM原生后端的运行时性能,成为编译器领域的新宠。 传统LLVM的-O0后端虽然追求生成代码的调试友好性,但在编译速度方面表现不尽如人意。主要瓶颈体现在代码生成环节的多步复杂流程,如繁复的寄存器分配、冗余的机器指令选择以及过度细化的中间表示处理等。TPDE-LLVM通过颠覆传统后端的架构设计,采用紧凑高效的单遍代码生成流程,将寄存器分配、机器码编码等步骤融合于一个统一过程,从而极大简化了后端的工作量,实现了惊人的构建速度。
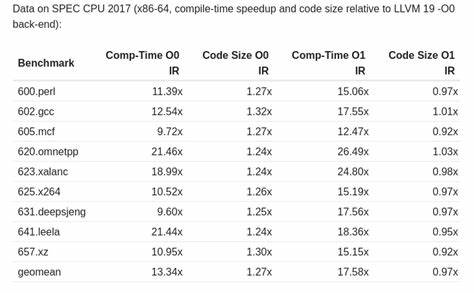
具体来说,TPDE-LLVM将在三大处理阶段完成核心工作。首先是IR(中间表示)清理与准备,通过分析并重写部分难以高效处理的常量表达式,快速简化输入阶段。接下来是一次循环与活跃变量分析的效率驱动型分析阶段,确保后续生成器能够精准定位代码热点和值生命周期。最后一个代码生成阶段集成了IR向底层机器码的直接转换、寄存器分配及编码操作,避免了多次往返中间表示的性能损耗。通过这种创新设计,TPDE-LLVM在SPEC CPU 2017基准测试中实现了平均约13倍(在-O0 IR)到17倍(在-O1 IR)的编译速度提升,且代码体积仅比LLVM原生后端略增约27%,确认了加速但不牺牲性能的可能。 TPDE-LLVM目前支持x86-64和ARM AArch64两个主流架构,并针对这两个目标实现了高度针对性的优化策略。
尤其是在AArch64架构上,通过借助GlobalISel技术,获得了略高于x86-64的性能加速。虽然相比针对优化级别较高的LLVM编译,TPDE-LLVM在运行时性能和代码体积方面还存在一定差距,但其专注于快速生成调试友好代码的定位,让它成为开发快速迭代、调试分析的理想选择。 然而,TPDE-LLVM目前仍局限于支持典型Clang生成的-O0至-O1 IR子集,尚未覆盖所有LLVM IR特性。例如,在对浮点操作的支持上存在瑕疵,部分Fortran代码表现不稳定。Rust语言的部分流行库也因使用未被本后端支持的矢量类型而无法完全兼容。关于矢量类型的合法化问题,是编译器领域中公认的复杂难题,未来的改进将继续关注对更多IR特性的扩展支持。
未来规划方面,TPDE团队展示出的雄心壮志涵盖了源代码调试体验的提升,如DWARF调试信息的支持原型已取得进展,进一步改善寄存器分配策略,解决现阶段“全部溢出”策略带来的性能瓶颈。对非ELF平台的支持、非小型位置无关代码模型的兼容性以及更多目标架构的扩展,都是潜在的开发方向。用户也可以将TPDE-LLVM作为库集成于JIT编译环境,或像传统lldc工具一样单独使用,现阶段虽仍需为Clang集成进行补丁开发,但未来插件支持有望进一步简化集成流程。 深入理解TPDE-LLVM背后的技术细节,有助于揭示为何无优化级别编译速度难以突破的本质原因。LLVM IR中存在大量需要重复访问和解析的复杂常量表达式,特别是函数内的ConstantExpr对处理过程构成瓶颈。TPDE-LLVM绕开这一难题,通过预先将此类表达式转化为指令序列,大幅降低编译时的递归复杂度。
类似地,对于包含庞大结构体或数组值的情况,传统LLVM编译时开销呈二次方增长,而TPDE-LLVM通过限制此类特性的支持,避免了编译时的爆炸式增长。 此外,TPDE-LLVM还体现出精妙的工程细节。例如,利用现成的指令填充字节存储唯一指令编号,优化代码块中具有大量前驱的基本块处理逻辑,改进PHINode的查找效率,缓存控制流后继节点从而避免频繁查询开销等。这些看似细微的改进汇集在一起,极大地提升了整体编译效率。 由于TPDE-LLVM的设计理念不同于常规LLVM优化后端,其不像编译优化那般追求终极运行效率而是聚焦于编译时间和调试用户体验,因而它并不妨碍在其他使用场景中选择LLVM的高优化阶段后端。可以说TPDE-LLVM为LLVM生态注入了新的活力,为多样化的编译需求提供了更丰富的选择。
未来随着社区投入及开发逐渐加深,有望见证其在更多编程语言、更广泛硬件平台以及更复杂IR结构支持上的突破。 总体而言,TPDE-LLVM的推出是编译技术领域一场令人振奋的创新,它不仅挑战了开发者对于LLVM -O0后端性能天花板的认知,而且为提升开发速度与调试效率打开了崭新的空间。随着开源代码的持续完善和功能扩展,TPDE-LLVM有潜力成为未来编译器设计的重要参考典范。在快速迭代与严谨性能之间寻找新的平衡,TPDE-LLVM铸就了高效、实用且柔性的编译后端蓝图,必将在开源社区和产业界激发更多探索与合作。