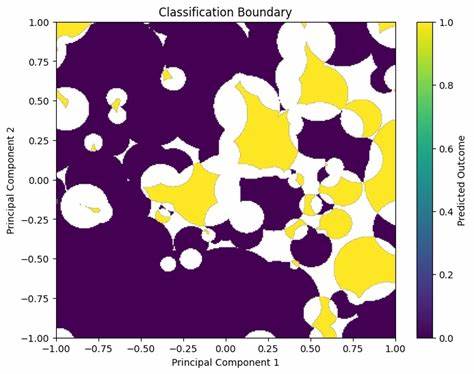
在当今数据驱动的世界里,算法性能的提升不仅关乎效率,更决定着分析的深度和业务的成败。作为一名数据科学家,我对如何优化算法处理速度抱有浓厚兴趣。最近,我将传统的Pandas框架下实现的Reduced Columb Energy (RCE)算法迁移到开源的Polars库,结果取得了惊人的性能飞跃,速度提升达到了惊人的25倍。这一转变不仅展示了Polars在数据处理上的优势,更为机器学习和数据分析领域的开发者提供了一条新的技术路径。Reduced Columb Energy (RCE)算法作为一种较为小众但别具特色的分类器,区别于大家熟知的K近邻算法。其核心思想是通过构建“命中足迹(hit footprints)”来判定样本的类别。
算法会围绕每个训练数据点构建一个以最近的异类样本距离为半径的球体,这些球体共同定义了该类的命中区域。当有未知样本需要分类时,若该样本落在某类别的命中区域内,则归为该类别。此方法在数据有限的情况下表现尤为出色,克服了传统K近邻对密集数据依赖较大的劣势。尽管RCE算法本身设计独特,但传统用Pandas配合lambda函数逐行计算距离的方法,导致其计算效率低下。每一个训练样本都需要计算与整个异类训练集的距离,时间复杂度极高,导致运行耗时较长。在实际测试中,基于Pandas的实现往往需要数分钟才能完成。
Polars的亮点在于其底层采用了多线程并行计算和Apache Arrow内存格式,其架构“贴近硬件”大幅减少了计算开销。Polars强烈推荐利用其表达式API进行列级操作,避免使用会打断优化和并行计算的Python lambda函数。基于这种理念,我对RCE算法进行了结构上的深度重构,摈弃了行级lambda计算,转而使用Polars的跨连接(cross join)与列式向量运算实现矩阵化距离计算。通过跨连接,将训练数据框与自身经过类标签过滤后的子集进行笛卡尔积关联,获得每个点与所有异类点的组合,接着通过列级表达式计算欧式距离的平方,实现批量化的距离计算。然后通过分组聚合找出最小距离,即每个样本的lambda值。相比Pandas的逐行调用函数,Polars这种方式充分利用了硬件的并行能力,同时避免了传统Python层在循环中频繁调用底层计算的性能瓶颈。
对推断阶段的分类操作,我同样采用了表达式API,将待预测数据点与训练阶段计算得到带有lambda半径的训练样本进行跨连接,批量计算两者之间的距离,并判定是否落入某类别的命中区。进而通过分组汇总命中次数,最终得出预测类别。这套流程完全基于Polars表达式链,保证了极高的效率和资源利用率。实际运行数据显示,Polars版本的RCE算法在同一硬件环境和数据集上,用时仅为传统Pandas实现的1/25,耗时由约6分钟缩减至14秒,性能提升显著。虽然跨连接策略在数据量巨大时会带来内存压力,但针对中小型数据集和工业级快速原型开发,已是极具吸引力的方案。未来需要继续探索数据压缩、分块处理等技术,缓解跨连接带来的存储开销,扩大方法的适用范围。
Polars的成功经验强调了现代数据处理框架的设计趋势:充分发挥列式存储、高效内存格式和多核并行计算,而非传统的逐行处理模式。开发者应更多关注底层数据结构和API设计,摒弃不适合并行计算的编程习惯,实现算法性能的跨越式提升。此次Polars对RCE算法的加速不仅验证了其实践价值,也为机器学习领域提供了新的思考角度,期待更多创新算法及系统架构的结合带来更强大、更灵活的解决方案。随着开源生态的演进,Polars及类似工具的普及,将在未来数据科学工作流程中发挥愈加重要的作用,推动行业实现更快速、更智能的分析落地。