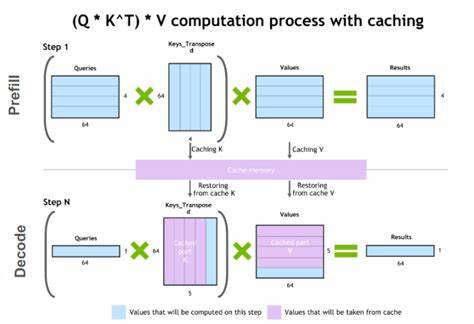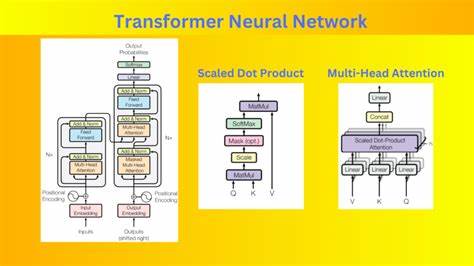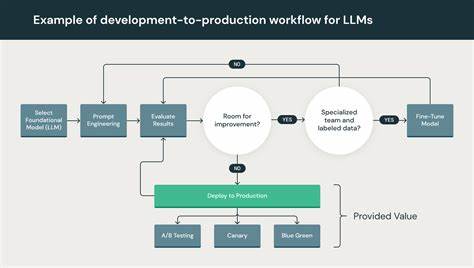
随着人工智能技术的飞速发展,尤其是在大型语言模型(LLM)领域的创新推动下,数据处理的重要性日益凸显。数据的质量和处理效率直接影响着模型的训练效果和应用表现。DataFlow应运而生,它是一款专为LLM数据准备和处理设计的智能系统,旨在提升数据处理速度、增强处理能力,并简化复杂的工作流程。DataFlow通过模块化的操作器设计与灵活的流水线组合,为用户提供了高效、精准且易用的解决方案,从而推动了多个行业内智能模型的落地和优化。DataFlow能够处理来自多样化、嘈杂数据源的信息,包括PDF文档、纯文本及低质量问答数据。通过集成规则方法、深度学习模型、LLM以及LLM API,它构建了丰富的操作器库。
这些操作器以结构化数据作为输入,通过智能处理生成高质量的输出,为下游任务提供坚实的数据基础。值得关注的是,DataFlow的操作器被划分为泛用操作器、领域专用操作器和评估操作器三大类别,涵盖文本处理、医学、金融、法律等专业领域,同时提供全面的数据质量评估能力,确保数据的严谨性与有效性。在流水线设计方面,DataFlow预置了多套成熟的流水线,涵盖文本挖掘、推理增强、自然语言到SQL的转换、知识库清洗及基于知识库问答对的检索增强生成(RAG)任务。这些流水线不仅提升了数据的结构化程度,也为模型训练的多样化需求提供了支持。此外,DataFlow配备了智能代理系统,能够自主分析任务需求,自动编写新的操作器,并将其巧妙组合成新的流水线,极大地减少了人工干预门槛,并提升了系统的灵活性和扩展性。其丰富的功能模块通过友好的Gradio交互式界面向用户开放,使得操作器和流水线的调用更加直观便捷。
用户只需简单的命令即可启动图形界面,体验从数据输入到结果输出的完整流程,极大降低了使用门槛。同时,DataFlow还支持本地GPU加速推理,满足高性能处理需求,适配Python3.10及以上环境,可轻松集成到现有的数据科学工作流中。DataFlow不仅是一套本地工具,亦提供基于云端的全托管SaaS服务——ADP智能数据平台。该平台以大规模多模态知识库融合、智能多代理协作与AI原生数据库管理为核心,帮助企业快速构建定制化代理和模型,推动数据驱动的智能解决方案规模化应用。实验数据表明,DataFlow在预训练数据筛选和监督微调数据处理上表现突出。通过对RedPajama数据集的优化筛选,保留了仅13.65%的高质量数据,却显著提升了数据在写作风格、专业知识含量、事实性和教育价值等多维度的质量评分。
类似地,利用其推理流水线合成的大规模问答训练数据,显著增强了模型的推理能力和回答准确率。此外,利用DataFlow构建的Text2SQL流水线通过结合监督学习与强化学习,不仅提高了自然语言查询的转换精度,还增强了模型对复杂数据库结构的理解能力。DataFlow背后的研发团队积极推动学术研究,发表了多篇围绕多模态推理验证、预训练数据选择机制等核心技术的权威论文,获得了国际会议认可。团队在2025年ICML自动化数学推理挑战赛和北京人工智能研究院主办的语言与智能挑战赛中均荣获首奖,体现了DataFlow在AI数据处理领域的领先技术实力。DataFlow的成功也离不开开源社区的活跃贡献。包括与MinerU团队在内的多个合作方为系统提供了强大的文本提取功能及工具支持,促进了数据的高效加载和清洗。
GitHub仓库拥有超过1400颗星,聚集了数十位贡献者共同推动项目进步,提供了持续的技术支持与创新。从应用角度来看,DataFlow广泛适用于医疗健康、金融风控、法律咨询等需要高度专业化语言模型的领域。在医疗领域,它能够从杂乱无章的医学文献和临床数据中提取结构化信息,辅助模型更准确地理解专业知识,提高诊断和治疗方案的智能推荐质量。在金融领域,通过处理海量政策文件、市场报告及法律条款,DataFlow极大提高了模型在风险评估、合规审查中的表现能力。在法律领域,面对法规文档复杂且多变的特点,DataFlow帮助构建了精准的法律知识库,提升了法律问答系统的响应准确度及用户体验。展望未来,DataFlow计划进一步深化多模态数据处理能力,强化对图像、表格、视频等多源异构数据的集成分析,通过人工智能技术提升数据语义理解的深度及广度。
同时,继续优化智能代理与操作器生态,推动自动化流水线的智能化升级,满足更多复杂场景的定制化需求。DataFlow不仅代表了当下数据驱动人工智能的前沿技术,也为行业用户提供了高效、专业的工具,助力大型语言模型技术向更多实际应用领域落地。伴随着社区的不断壮大和技术迭代,DataFlow将持续释放其潜力,推动数据处理与智能模型训练的融合与创新,助力中国乃至全球人工智能产业迈向新的高度。