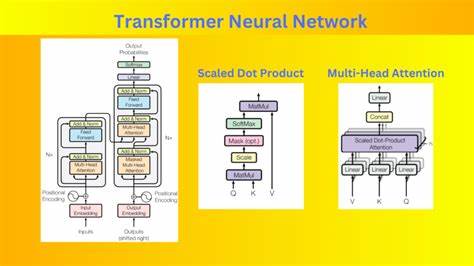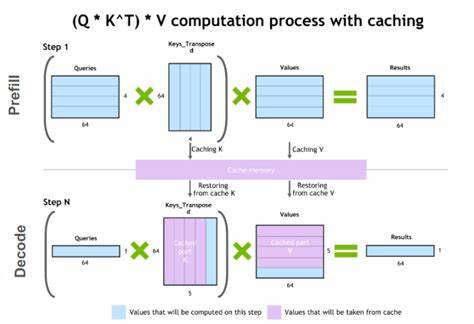
近年来,随着大规模语言模型(LLM)在自然语言处理和人工智能领域的迅速发展,如何高效地管理和利用模型的前缀缓存(Prefix K/V缓存)成为提升系统性能和用户体验的关键。LLM-d中的Prefix K/V缓存技术,作为一种存储与访问先前计算状态的创新手段,极大地推动了多轮对话和复杂场景下模型推理的效率优化。其设计理念及实现方式具有重要的行业参考价值。前缀缓存的核心目的是保存和复用之前对话或输入过程中已计算的键值对信息,避免重复计算,从而提升推理速度和系统响应能力。这在多轮交互式应用场景尤为关键,因为用户互动往往存在高度的时间相关性和上下文依赖,缓存能够极大减少计算资源浪费和延迟。LLM-d采用分层缓存体系结构,将前缀缓存分为多种类型以匹配不同的使用需求和硬件资源。
其中包括高带宽存储(HBM)前缀缓存、主机内存前缀缓存、东西向(E/W)网络前缀缓存及远程前缀缓存等。每种缓存均针对特定的设计目标进行优化,既保证了缓存的命中率,也兼顾资源利用和系统扩展性。高带宽存储前缀缓存主要用于快速响应短期且频繁的查询请求,适合高并发环境;主机内存前缀缓存则提供容量较大但访问延迟稍高的存储空间,适用于中等规模数据缓存;东西向网络缓存针对拥有多GPU集群的分布式系统,利用东-西向数据流提升不同计算节点间的缓存共享效率;远程缓存则更适合跨数据中心和更大范围的分散式架构,实现跨地域缓存同步和负载均衡。为了兼顾不同场景下的性能表现,LLM-d提出了可插拔的前缀缓存抽象方案,使得存储层的切换和扩展更加灵活。这种设计方便了生态系统整合者根据具体需求定制缓存层级和策略,极大地提升了部署的适应性。例如,最先实施的方案包括将高带宽存储缓存与主机内存缓存联合采用,并运用LRU(最近最少使用)算法自动调整缓存容量与模型服务器负载,确保缓存命中率最大化且自适应变化的业务需求。
东-西向优化缓存则针对8GPU集群进行配置,优化IO路径和网络带宽,提升跨节点缓存访问效率。未来的方案蓝图则聚焦缓存进一步向SSD和对象存储后端迁移,实现更大规模、异构设备环境下的缓存共享。与此同时,标准化缓存条目发现和管理机制的推进,将使缓存系统更易于维护与协作。技术挑战层面,LLM-d特别关注缓存背压(backpressure)问题,即当前缓存资源受限导致下游请求阻塞的风险。为此,设计团队提出缓存自调节机制,既保证缓存热数据的持续可用,又避免缓存过载引发系统性能波动。此外,缓存的预热及热点复制策略对于维持多轮对话中高访问频率的数据命中率至关重要。
多种备选方案并行探索,有远程缓存服务、P2P集群内存缓存及东-西向加速器网络缓存,进一步为不同架构和规模的系统提供最优支持。值得一提的是,前缀缓存不仅仅限于模型推理性能优化,它在数据安全、模型隔离及故障恢复等方面同样具备潜在价值。缓存状态的分布式备份和异地多活能力,能够在节点故障或网络波动时保障系统连续性,实现更高的服务可用性和业务稳定性。结合当前人工智能模型和系统架构的发展趋势,LLM-d前缀缓存技术未来还将继续借助云计算及边缘计算资源,实现更智能和自适应的缓存管理。以更精细的实时监控为基础,系统将能动态调整缓存策略,优化缓存条目生命周期管理,应对复杂多变的业务压力。同时,缓存交互的智能路由与调度能够减少网络开销,提升异构计算环境下一致性和速度同步。
综上所述,LLM-d的Prefix K/V缓存技术充分体现了先进的存储架构设计理念与多层次协同优化思路,不仅为多轮交互式语言模型提供强有力的性能支撑,还展现了在大规模分布式计算环境下实现高效资源利用和可扩展性的广阔前景。未来,随着模型规模和服务复杂度的不断提升,前缀缓存方案将成为确保智能应用平稳、高效运行的关键保障,并逐步成为行业标准的重要组成部分。