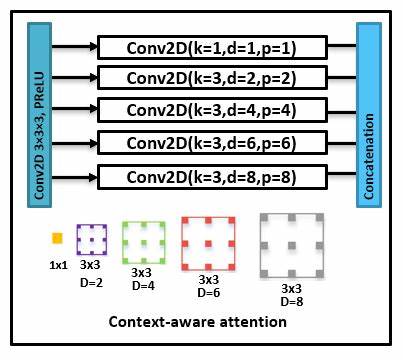
随着人工智能技术的飞速发展,Transformer架构已成为自然语言处理、计算机视觉及其他领域的主流基础技术。然而,Transformer的自注意力机制虽然强大,却面临着严重的复杂度瓶颈。这种机制在处理长序列时,其计算和内存需求呈现平方级增长,使得模型在面对超长文本、长视频等任务时,效率和应用范围大大受限。为了解决这一问题,学术界和工业界持续探索线性注意力机制,它们试图将计算复杂度降低到线性,但多数现有方案往往以牺牲模型性能为代价,采用了数据无关的核近似或限制性的上下文选择方案,导致注意力的精确性和上下文感知能力不足。针对这一难题,来自Zhongpan Tang的最新研究提出了TLinFormer,一种基于连接主义原理重构神经元连接拓扑的新型注意力架构。TLinFormer以独特的结构设计实现了严格的线性时间复杂度,同时计算精确的注意力分数,确保信息流始终保持对完整历史上下文的感知。
该设计理念不仅突破了传统线性注意力方法的性能瓶颈,也有效桥接了与标准Transformer注意力机制之间存在的性能差距。TLinFormer的核心创新在于重新配置神经元的连接模式。从连接主义的角度来看,信息在网络中的流动路径决定了模型对上下文的捕捉能力。传统Transformer通过全连接的自注意力机制实现全面上下文感知,但复杂度高昂。而TLinFormer通过巧妙设计的连接模式,保留了完整上下文的信息流动路径,但显著减少了计算冗余,使得计算过程严格符合线性时间复杂度。相较于近似方法,TLinFormer无需对注意力矩阵进行核函数逼近,因此保证了计算的精确性。
该模型在多项长序列推理任务中展现出卓越的性能表现。实验结果显示,TLinFormer在推理延迟、键值缓存效率、内存占用以及整体加速比等关键指标上,均优于传统Transformer和现有多种高效线性注意力机制。尤其在处理极长文本时,TLinFormer的优势更加明显,体现了其良好的可扩展性和实用价值。此外,TLinFormer在实际部署中展现出出色的KV缓存管理能力,极大减少了重复计算,从而有效提升了推理速度和能耗效率。这对于需要实时响应或资源受限的应用场景尤为重要。TLinFormer的出现标志着注意力机制设计理念的重大突破。
它不仅为解决长序列任务中的复杂度瓶颈提供了切实可行的方案,也丰富了连接主义理论在深度学习领域的应用实践。未来,随着该技术的不断完善与扩展,有望推动更多基于Transformer的应用深入发展,涵盖自然语言理解、视频分析、序列建模等多种复杂任务。总的来看,TLinFormer在理论创新和工程实现上均具备里程碑意义。它通过精准的注意力计算和高效的结构设计,打破了传统线性注意力方法的性能天花板,为长序列学习带来了更高效、更准确的解决方案。对于研究者和实践者而言,深入理解和应用TLinFormer将极大促进Transformer及其衍生技术的持续进步,推动人工智能技术迈向更智慧和更广泛的应用前沿。 。









