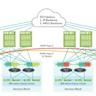
计算机运行的效率与内存访问模式密切相关,尤其是随机访问和顺序访问之间的性能差异,长期以来一直是程序优化的重要课题。现代计算机架构拥有多级缓存体系,包括L1、L2、L3缓存,每一级缓存的访问速度相较于主内存有着数量级的提升,而内存操作通常以缓存行(Cache Line)为单位进行传输,大小约为64字节。理解如何利用这些机制来最大化性能是程序员设计高效算法的关键。本文通过实测和分析,深入探讨随机访问到底慢多少,以及其背后的原因和运行机制。首先,需要明确什么是随机访问和顺序访问。顺序访问指的是按照数组或内存顺序依次读取元素,这种访问模式利用了数据的局部性,能够最大限度地利用CPU缓存,减少访问主内存的次数,提高速度。
随机访问则指以任意顺序访问数组元素,往往导致频繁的缓存未命中,需要不断从较慢的主内存甚至磁盘读取数据,从而明显降低执行效率。实验设计中,作者以浮点数数组和对应索引数组为例,通过两种访问模式对相同数据进行累加操作。实验环境涵盖了两台配置不同的机器,分别是配备16GB内存和1TB固态硬盘的2020款MacBook Pro M1芯片笔记本,以及拥有24GB DDR4内存和1TB SATA SSD的Linux桌面电脑。通过运行多次测试并剔除前期缓存预热的数据,获得了稳定的性能指标。实验数据显示,当数组大小小于缓存容量时,顺序访问和随机访问的性能差异微乎其微,访问时间维持在每元素约一纳秒到半纳秒的水平。随着数组超出L3缓存容量,顺序访问仍保持稳定速度,进入主存访问,而随机访问速度明显下降。
MacBook Pro中,随机访问大约比顺序访问慢四倍;而Linux平台上,延迟提升甚至达到8到16倍。数组继续扩大到超过物理内存容量后,两种访问模式的访问延迟都急剧增加,随机访问的性能劣势更加显著。实验也考察了采用内存映射文件(Memory-Mapped File)技术对大数据量文件的访问效果。结果表明,内存映射虽然在便利性上优势明显,但在随机访问的大规模数据场景中性能表现与直接读写相差无几,且不同操作系统的表现存在差异,Mac系统中随机和顺序访问的速度趋于一致,而Linux系统则依然表现出随机访问明显更慢的趋势。除此之外,数据生成中的随机索引也影响整体性能。常用的Fisher-Yates洗牌算法在内存容量允许的范围内有效且性能可控,但当数组过大无法容纳于内存中时,其单阶段一遍洗牌的速度显著下降。
相应地,改用先将数据划分为约1GB大小的多段,再分别洗牌的两阶段算法,有效解决了这一瓶颈。对比实验进一步将单次从文件直接分块读取并求和与内存映射的方式进行了比较。结果显示,直接读取的效率在Mac系统上普遍优于内存映射文件,提示操作系统在处理大数据文件时缓存管理策略的差异。值得关注的是,实验中Linux系统的随机访问还在达到内存容量临界点之前就开始显著变慢,显示处理器缓存和内存子系统的差异对高性能计算的影响深远。此外,多次实验验证了缓存大小并非判断性能转折点的唯一标准,因为软件层面的页面管理、硬件预取机制、SSD带宽等因素共同作用。综上所述,随机访问相较顺序访问的性能劣势主要体现在缓存未命中和内存带宽受限两大方面。
顺序访问能最大化利用CPU缓存行,降低访问延迟;随机访问则导致频繁的内存访问请求和页面错误,使延迟提升数倍甚至数十倍。对于数组较小且完全适合缓存的情况,性能差距可忽略不计。而当数据量超出缓存,尤其超过RAM容量时,随机访问的慢速特性变得尤为显著。实践中,程序设计应尽量减少随机访问比例,利用顺序访问以提升内存访问效率。开发者还应评估自身硬件环境,调优数据结构和访问模式,以获得最佳性能。此外,内存映射文件虽方便操作大规模数据,但其性能表现受操作系统优化策略影响较大。
对于性能敏感的应用,针对不同系统和存储设备进行针对性测试与调优显得尤为重要。未来,随着硬件技术的发展和软件内存管理算法的优化,这些性能差距有望得到进一步缓解。理解当下架构与访问模式的互动机制,有助于开发者编写既高效又具可移植性的代码,推动计算性能和用户体验的双重提升。通过本文的分析和测试结果,希望能够帮助广大技术人员深入理解随机访问的性能本质,在设计及优化程序时作出更明智的选择,避免执迷于表面数据,抓住影响性能的根本因素,创造更高效、更稳定的计算应用环境。