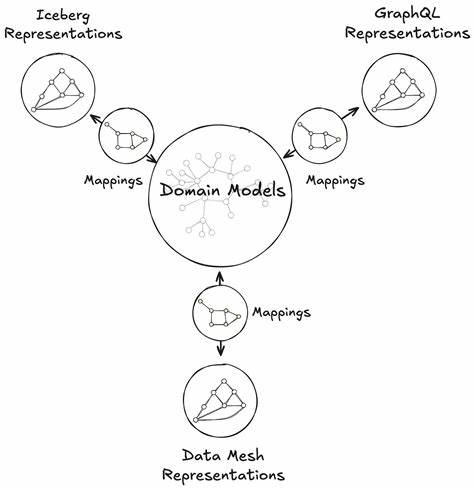
在当今数据驱动的时代,企业面临着庞大且多样化的数据挑战。Netflix作为全球领先的流媒体平台,如何高效地处理海量用户行为数据,并将数据转化为精准业务洞察,一直备受关注。统一数据架构(UDA,Unified Data Architecture)的提出,正是Netflix在数据工程领域的一次重大创新。UDA通过实现模型一次构建、处处应用的理念,解决了数据孤岛和模型碎片化等行业痛点,推动了从数据采集、模型训练到业务应用的全链路高效运行。 Netflix拥有庞大的用户基础和丰富多样的内容库,每天产生海量的观影行为数据、设备使用数据以及用户偏好信息。传统的数据架构往往依赖多个独立系统分别处理不同类型的数据,这不仅增加了复杂性,也导致模型重建频繁,训练资源浪费严重。
UDA的核心目标就是打破这些壁垒,构建一个统一的数据平台,实现数据和模型的集中管理与共享。 在UDA中,“模型一次构建”是其最显著的特点。Netflix通过统一的数据流程对原始数据进行预处理和特征工程,训练通用的表示模型。这些模型能够捕捉用户行为的深层次语义信息,进而生成高度抽象和通用的用户或内容向量表示。这样的模型经过训练后,可以在推荐系统、广告投放、内容分类乃至搜索排序等多个业务场景中直接复用,极大提升了模型开发的效率和一致性。 统一数据架构的设计理念不仅关注模型的复用性,更强调数据的质量和流转效率。
Netflix利用流式数据处理技术,实现数据的实时采集和更新,保证模型输入的时效性。同时,采用高度自动化的特征工程流水线,降低了人工干预和运维成本,使得数据科学家能够更专注于模型创新与优化。 通过UDA,Netflix实现了跨团队的数据协同。不同的业务团队可以基于统一的用户或内容表示,快速构建针对具体业务需求的算法和服务,避免了重复造轮子。统一的架构也带来了更加透明和可追溯的模型管理能力,有助于提升模型的公平性、可靠性和安全性。 此外,UDA还促进了模型的持续迭代。
借助灵活的训练框架和自动化评估机制,Netflix能够快速捕捉用户行为变化,持续改进模型性能。这样的闭环机制确保了产品体验能够随着数据积累不断优化,有效地应对市场环境的动态变化。 Netflix的统一数据架构代表了当下大数据与人工智能结合的前沿趋势。它通过“一次模型训练,处处表现”的理念,破解了传统多模型、多平台协同难题,为智能推荐和个性化服务提供了坚实的底层支撑。随着数据量的不断增长和业务需求的多样化,统一的数据管理和模型复用能力将成为提升竞争力的关键。 未来,UDA还将结合更多先进技术,比如联邦学习、隐私保护计算等,进一步提升数据安全和用户隐私保护水平。
同时,借助自动机器学习(AutoML)和深度学习模型架构搜索,Netflix能够不断发掘数据的潜能,驱动更智能、更精准的内容分发和用户服务。 总之,Netflix的统一数据架构不仅是技术层面的革新,更是一种打造数据与算法深度融合的战略布局。它为其他大型互联网企业提供了宝贵的借鉴路径,展现了如何通过合理设计架构,实现数据资产的最大化价值,为用户带来卓越的数字体验。在未来数据与智能不断融合的时代,Netflix的UDA无疑是一座标杆,彰显了数据驱动发展模式的无限可能。









