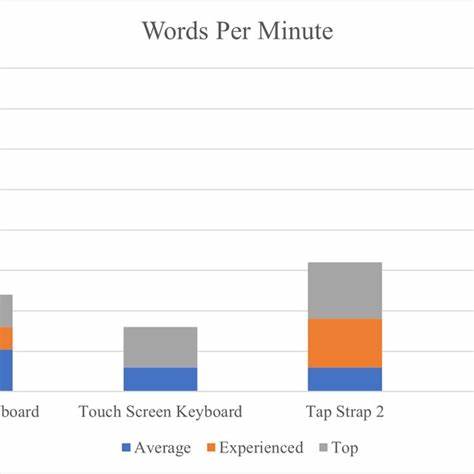
随着互联网服务对稳定性和实时监控需求的不断增强,健康检查服务成为保障任务调度和系统运行的重要工具。面对HTTP请求量的剧烈波动,尤其是由周期性cron任务引起的瞬时高峰流量,如何确保健康检查系统具备高吞吐量和低延迟响应性能成为技术团队必须攻克的难关。本文将结合具体实践,深入分析健康检查开源项目在请求处理上的吞吐量升级策略及其架构进化过程,通过列车运输的形象插图解读背后关键技术点,带您理解构建高效请求处理系统的秘籍。健康检查监控涉及大量的ping请求写入数据库,尤其在每分钟及每小时的关键时刻,写入量会猛增。例如平均情况下一秒约有500个ping写入请求,到每分钟开始时峰值跃升至4000个每秒,而每小时开始时甚至超过一万每秒。原生Python结合Django ORM的处理逻辑可以稳定支持数百请求每秒,但面对生产环境的数千乃至万级请求时,Python方案则显得捉襟见肘。
于是团队开发了基于Go语言的闭源ping处理服务,通过高效的并发协程和数据库存储过程,极大提升了写入吞吐能力。早期设计中,单个worker协程通过PostgreSQL中的存储过程原子化执行SELECT、UPDATE、INSERT及DELETE操作,确保数据一致性和性能。这里可用列车运输做类比:数据库事务像一列列载满货物的火车,worker就像矿工定期将煤炭装车运送到发电厂。由于采用单连接顺序处理,保证了每次事务只需一次数据库往返。这种设计曾经应对不断增长的请求量表现稳定,团队后续增加worker数量,让多条“轨道”并行作业,累计提高整体吞吐率。在2021年开始,两worker并行增加系统吞吐,2024年升至三worker,2025年发展到四worker,多台服务器同步工作,使并发协作达到12个顺序写入流。
尽管加速显著,仍存在性能瓶颈,尤其数据库写入成为限制。为突破瓶颈,升级方案从单条数据请求处理转向批处理策略。首次尝试通过将多笔请求合并成数组传入PostgreSQL存储过程,利用循环调用原有写入逻辑,试图减少数据库连接数和往返次数。尽管理论上能节省开销,实际中遇到复杂性增加、调试困难和性能提升有限的问题,最终由于严重BUG,团队放弃了这套方案。随后,团队没有放弃批量处理思路,而是转向利用PostgreSQL的COPY协议,该协议以极高效写入大量数据著称,特别是在五条以上记录插入时性能优于常规INSERT语句。基于这一点,团队设计了结合批量构建和COPY插入的新架构。
具体流程为,HTTP请求被http handler验证后打包成Job对象放入缓冲通道。worker协程从通道中汲取Job,按照批次大小上限或延时阈值收集足够请求构成批次。批量请求启动数据库事务,执行单条查询批量获取相关检查数据,对每个检查逐条异步更新状态,最后通过单次COPY复制大批ping记录入数据库完成写入。事务提交意味着整批请求成功落库。该设计除了显著提升数据库使用效率,也减少了网络往返和CPU处理压力。设计中需解决验证标识符、动态创建检查项、避免死锁的排序策略及旧数据定期清理等功能,确保系统正确性和可靠性。
另一个突破是多worker协作,这不仅提高吞吐,还降低平均请求延迟。通过让一个worker提交当前批次事务,另一个worker并行组装下一批任务,并通过互斥锁防止争抢,实现流水线式协作。这样既保证单批次处理的原子性,也避免了等待时间积累,引发性能瓶颈。经过多轮迭代,目前架构在高峰阶段能平稳支持逾一万请求每秒,开发环境下甚至达到两万,同时维持响应时间稳定,无长时间积压。回顾整个升级过程,硬件性能的提升,PostgreSQL内核优化,以及精细的批量处理策略,是吞吐量大幅攀升的关键。未来若流量仍持续增长,则可能考虑硬件纵向升级、参数调整,甚至数据库分片与负载分配技术整合。
总结来说,通过将单一协程同步处理转变为多worker异步批量处理,搬移部分数据库逻辑至应用层,利用COPY协议实现高效写入,健康检查系统成功突破了单点性能瓶颈,满足了现代云环境下的高并发稳定需求。使用列车运输的比喻,数据库事务像火车依序运输货物,多条轨道并行协同作业,减少了等待时间,实现了吞吐量飞跃。对于务求构建高性能、可扩展、具备快速故障恢复能力的监控系统开发者而言,本文所解析的设计策略与技术实现具有重要借鉴意义。未来,随着软硬件的不断进步,相信类似的升级方案将继续成为提升分布式系统数据处理能力的核心参考范本。