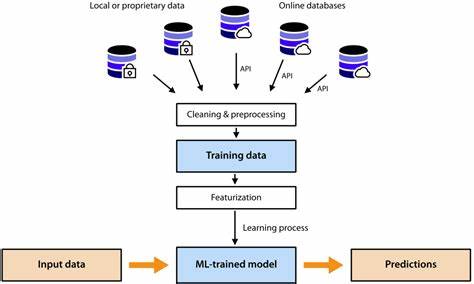
随着人工智能和机器学习技术的迅速发展,训练大规模机器学习模型的需求日益增长。面对日益复杂的训练任务和庞大的数据处理需求,选择合适的训练作业提交工具成为了提升开发效率和模型性能的关键。本文深入分析各种机器学习训练作业提交工具和平台,探讨它们的特性、优缺点及适用场景,帮助从业者做出明智的选择。 机器学习训练作业提交工具的核心目的是简化训练任务的管理,自动化资源调度,并在多种计算环境下高效运行。通常,这些工具需兼顾易用性、扩展性和资源利用率。在众多工具中,既有云端平台,也有开源框架,为用户提供了多样的选择。
云计算平台因其高度的弹性和丰富的算力资源,成为许多企业训练机器学习模型的首选。亚马逊AWS的SageMaker、谷歌云平台的AI Platform和微软Azure Machine Learning均提供端到端的机器学习工作流支持,涵盖数据预处理、模型训练、调参和模型部署。利用这些平台,用户无需担心底层基础设施,能快速启动训练任务并进行大规模并行计算。 另一方面,开源作业调度和管理工具在研究和企业中同样受欢迎。平台如Kubernetes和Kubeflow帮助构建灵活的训练环境,通过容器化管理训练任务,实现跨集群资源调度和弹性扩展。Kubeflow专为机器学习设计,支持复杂的训练工作流,方便集成TensorFlow、PyTorch等主流框架,极大地提升实验复现性和团队协作效率。
除了以上平台,还有针对特定场景的作业提交工具。例如Ray是一个灵活的分布式执行框架,支持大规模并行计算和自定义训练流程,适合需要高度定制化训练任务的开发者。Slurm等高性能计算作业管理系统则广泛应用于科研机构和超级计算中心,帮助优化资源分配和任务调度,提升计算密集型机器学习训练的效率。 选择合适的训练作业提交工具需要综合考虑多个因素。首先是训练任务的规模及复杂度。对于初创团队或中小型项目,云平台的托管服务可迅速搭建环境,降低维护成本。
而大型企业或科研机构则更适合部署自定义的分布式资源管理工具以实现更高的灵活性和控制力。 此外,开发团队的技术水平和现有生态环境也影响工具的选择。云平台多采用图形界面和丰富的API,便于快速上手和集成第三方服务。开源工具往往需要更高的运维技能,但能深度定制训练管道和资源策略。与数据存储系统、版本控制和监控工具的兼容性同样重要,以保证训练流程的整体稳定性和可追溯性。 使用训练作业提交工具还需关注模型的可扩展性和性能优化。
合理划分训练任务,利用分布式训练框架减少训练时间,是提升效率的关键。动态资源调度和自动弹性伸缩功能则帮助应对训练过程中的负载波动,节约计算资源和成本。此外,系统应具备良好的故障恢复能力,保障训练作业的连续性与数据安全。 在实际应用中,许多团队结合多种工具形成混合架构。例如,使用Kubeflow构建本地训练环境,同时借助云平台进行大规模超参数调优。通过这种方式,既能保持自主控制,又充分利用云计算的弹性优势。
积极探索自动化流水线和智能调度技术也是未来的发展趋势,帮助加快模型迭代和部署速度。 总的来看,机器学习训练作业提交工具的选择和应用是一个兼顾技术、业务和运维的综合过程。合理评估需求和资源,结合行业最佳实践,能显著提升训练工作的效率和质量。未来,随着技术的演进和生态的丰富,这些工具将更加智能化和易用,持续推动机器学习领域的创新和发展。









