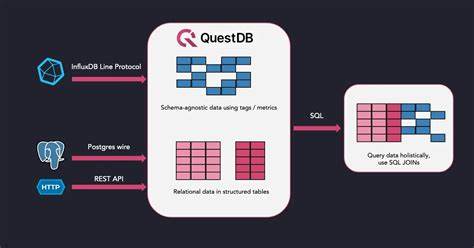
QuestDB作为一款开源时间序列数据库,凭借其从零开始构建的设计理念和极致追求性能与效率的技术实现,迅速赢得了金融、物联网以及加密货币等行业的广泛应用。自2013年由现任首席技术官Vlad Ilyushenko在开发交易系统时因传统数据库性能限制萌生的构想,到2019年正式成立公司,再到成为YC支持的高成长初创企业,QuestDB始终保持着对时间序列数据处理的专注与深入。在这篇文章中,我们将全面解读QuestDB的设计架构及内部实现,揭秘其高效运作背后的技术机理。QuestDB的设计核心围绕着高速写入、低延迟查询及易用性展开。其开源版本通常以单节点部署为主,利用云端虚拟机结合持久化存储卷实现数据持久化。虽然备份与恢复功能内置在开源版本中,但多节点高可用集群及复制功能则限于企业版提供,其还规划了即将推出的多主写入特性。
多主写入架构采用由Foundation DB集群管理的全局唯一自动递增事务ID,确保多个客户端写入时数据一致性和顺序,其元数据存储也统一托管。此外,QuestDB支持多种数据接入方式,除了官方提供的客户端库外,还兼容InfluxDB Line Protocol(ILP)格式,简化了老用户和其他系统的数据迁移。查询语言上,QuestDB完美兼容PostgreSQL的大部分语法并支持自定义扩展,融合了精准的时间序列分析功能,如"SAMPLE BY"语法,极大便利用户针对不同时间粒度进行数据聚合。技术实现方面,QuestDB采用了独具匠心的Java开发风格,类似于Chronicle项目,性能关键部分通过C语言编写并借助JNI桥接执行。Java端大量运用Unsafe操作及手动内存管理,显著减少垃圾回收带来的性能抖动。奇妙的是,QuestDB不依赖外部库,保证了零依赖的打包与嵌入能力,甚至支持嵌入式模式嵌入Java应用。
此外,项目在底层采用了SIMD向量化、IOUring异步IO以及自定义JIT编译过滤器等多项先进技术来提升性能。存储模型同样体现了对时间序列数据特点的深刻理解。数据表按照时间进行分区,最小粒度为小时级,类似于数据的时间轴被细分为精确的时间切片。每个分区内以列文件存储数据,变量长度列如字符串和二进制数据的存储采用数据文件与偏移文件分离方式,优化数据访问效率。更重要的是,分区内的数据按"指定时间戳"列保持有序,提升了时间序列查询性能。QuestDB还实现了基于字典编码与位图倒排索引的SYMBOL类型,用于提升高基数字符串标签的查询速度。
针对数据写入,特别是系统监控或日志场景中常见的重复数据问题,QuestDB支持按配置的列集作为合并键实现去重及Upsert逻辑。对无序写入(Out-of-Order,O3)也有成熟的解决方案,无论是针对较近时间的数据重新排序尾部文件,还是较远数据触发分区拆分,有效降低了写放大和数据混乱。写时日志(WAL)设计则为每个表和连接独立管理,再通过全局序列器分配全局唯一递增事务ID,保证读写一致性。WAL还支持处理O3写入和去重机制。数据备份方面,QuestDB提供检查点模式辅助用户备份,虽然该过程目前依赖于手动触发且可能导致服务短暂停机,但企业版则有更为高级的备份和快照功能,允许在重排序期间继续服务查询。查询功能上,QuestDB继承了PostgreSQL的丰富SQL功能,同时增加面向时间序列的语法扩展和图表工具连接支持。
虽然尚未支持PromQL,但提供了兼容Grafana和Superset查询构建器的接口,提升可视化监控体验。数据库支持多种JOIN操作,包括时间相关的ASOF等类型连接,满足复杂分析需求。高性能查询得益于全堆外内存管理、JNI桥接调用高性能C++代码,以及多种定制数据结构实现。QuestDB在关键计算逻辑中使用定制向量化哈希表和SIMD指令加速聚合,在x86平台上采用JIT编译过滤器将查询条件预编译为机器码执行,进一步降低CPU时间消耗。其大量采用零拷贝的直接内存访问和内存映射文件,结合位图索引和时间分区,在保证数据访问高速的同时减少磁盘IO瓶颈。值得一提的是,虽然主流I/O是基于mmap实现,IOUring的异步能力目前主要应用于复制任务,显示QuestDB团队对性能优化路径的稳健规划。
QuestDB的查询执行模型采用异步消息驱动机制,类比于LMAX Disruptor设计,内部构建了自研的线程间消息系统,贯穿数据摄取至查询执行的全流程。查询处理被切分为多条PageFrame序列,由专门线程异步调度与执行。PageFrame支持多种底层数据格式,包括原生QuestDB格式与Parquet页,彰显其对异构数据格式的兼容与未来演进潜力。该异步任务队列允许执行线程自我调度和负载均衡,优化多核资源使用和查询响应速度。性能优化方面,QuestDB团队设计并实现了多项创新技术。VarChar类型通过存储字符串6字节前缀以加速比较操作,灵感源自Umbra数据库的"German Strings"设计。
同时,使用自定义UTF-8字符串序列表示(Utf8Sequence),避免Java字符串内部转换,保证字符编码统一且高效处理,结合SWAR优化提升LIKE操作性能。自研的多种数据结构,比如无界越界检查的IntList,和直接内存版本的LongList,最大限度减少运行时开销和JNI跨语言调用阻塞。JIT编译过滤器前端由Java实现,后端通过基于asmjit的C++完成汇编代码生成,不依赖第三方LLVM框架,降低依赖复杂度并提高启动速度。通过此方式,QuestDB能够快速生成适合大规模数据集的本地代码,实现极致过滤效率。哈希表方面,QuestDB提供多种针对具体数据类型的定制实现,普遍采用开地址线性探测法并调整低负载因子(约0.4),提高高基数组聚性能。部分哈希表如名为"Rosti"的C语言实现,服务于向量化批量聚合操作,利用JNI连接高速执行环境,克服语言跨界性能瓶颈。
QuestDB正积极向第三类型架构演进,通过Rust实现存储与计算分离,支持直接从对象存储中读取QuestDB原生格式及Parquet、Iceberg等开源格式数据。其自研Rust版Parquet读取器性能领先官方实现10至20倍,并推荐结合arrow2库进行数据解析,体现了QuestDB在现代数据生态开放集成上的布局与野心。整体来看,QuestDB作为专注时间序列数据处理的数据库系统,从底层存储设计、内存管理与语言选择、查询执行模型、再到针对具体场景的代码优化,皆体现出极强的工程能力与技术积累。在与ClickHouse、StarRocks等领域顶尖竞争者较量中,QuestDB凭借其创新架构、多语言技术融合及对时间序列特性的深刻理解,持续保持良好市场口碑与用户认可。未来随着企业级高可用、多主写入及面向云原生的Type-3架构逐步完善,QuestDB有望成为时间序列与分析型数据库市场不可忽视的重要力量。阅读QuestDB的设计细节,不仅能洞悉高性能数据库的构建思路,也为开发者和数据工程师提供了宝贵的技术借鉴和启发。
无论是时间序列数据的实时处理,还是面向大规模分析的异构存储与计算分离,QuestDB都代表了未来数据库技术发展的一个重要方向。 。