在现代数据驱动的商业环境中,企业对数据摄取和分析的需求不断攀升,面对日益增长的实时数据流量,传统的单写入实例架构逐渐暴露出瓶颈,难以满足大规模、高吞吐量的数据摄取需求。作为开源的列式数据库,ClickHouse以其极致的查询性能和大规模数据处理能力受到了广泛欢迎。然而,随着客户数据量的激增,单一写入实例遇到了吞吐限制,成为制约整体系统性能的关键因素。为了应对这一挑战,Tinybird团队探索并实践了多写入架构,从而实现了ClickHouse摄取能力的横向扩展和系统稳定性的提升。 多写入架构的核心思想是将摄取负载分散到多个ClickHouse写入实例,避免单点瓶颈带来的性能限制。这种方案不仅保证了数据写入通路的并发能力,还有效隔离了各写入节点的故障风险,提升了整体的数据摄取弹性。
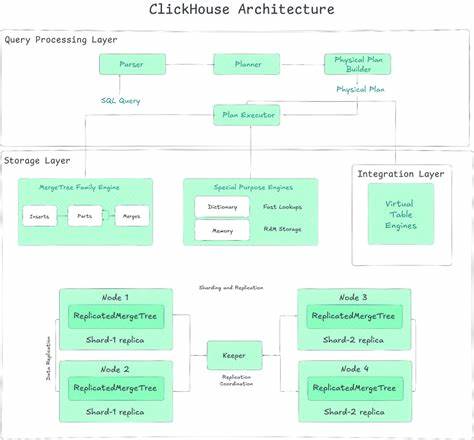
Tinybird的解决方案通过启用多写入模式,使实时摄取路径可以将特定表或整个工作空间的数据流量路由至不同的ClickHouse写入实例,形成负载均衡且高可用的数据摄取体系。 传统的ClickHouse集群通常采用计算与计算分离(compute-compute separation)设计,将写入集中在单一专用副本以确保读取性能不受摄取负载影响。然而,当面对海量数据量时,这种架构往往难以突破单一写入节点的吞吐瓶颈,导致数据延迟增长,甚至影响集群稳定。为此,多写入方案不仅是纵向扩容的补充,更是系统可持续发展的必由之路。 在多写入架构的实现过程中,团队最初考虑了动态负载均衡与哈希路由方案,试图实现自动化且细粒度的流量分配。然而,这些方法增加了系统复杂度,调试难度加大,且在高负载情境下可能引发难以预料的错误和故障。
团队最终选择了静态路由策略,以配置明确的路由规则,在数据源级或工作空间级别指定数据写入目标,实现简洁、可控且稳定的流量分发。 负载均衡策略的核心组件是Varnish代理,负责将写入请求路由至合适的ClickHouse写入实例。早期通过Jinja模板在Varnish配置中添加条件逻辑实现路由判定,虽然能够支持多写入目标的基本路由需求,但当某个写入副本故障时,所有流量回落至单一主写入实例,依然带来潜在风险。 为提高故障自动恢复能力,团队开发了基于C语言的自定义Varnish模块(VMOD),提供backend_by_index()函数,将写入流量智能分配至第N个健康的后端实例。该机制实现了写入请求的动态健康检测和自动切换,保障即使部分写入副本宕机,系统依然能够平稳运转,最大限度减少故障影响。 在真实生产环境下,多写入架构经过逐步验证。
针对客户每日高峰时段摄取流量突然剧增的场景,多写入设计有效分散了写入压力,使得集群内存资源压力得以缓解,延缓了系统达到瓶颈的时限。数据摄取系统变得更加弹性与健壮,能持续满足业务不断增长的实时数据需求。 通过多写入方案,Tinybird不仅实现了ClickHouse摄取架构的水平扩展,还强化了系统的可维护性和运维效率。具体表现为简化了路由配置,易于定位和排查问题,同时提升了容错能力,减少了因实例故障导致的业务中断风险。这样的改进为用户提供了稳定、高效的实时数据服务保障。 对于企业级用户而言,采用多写入ClickHouse架构意味着其分析平台可以从容应对海量日志、事件、用户行为等高速增长的数据流,确保业务分析报表和下游加工系统的数据实时性和准确性。
尤其是在数据驱动决策日益重要的背景下,提升数据摄取性能赢得了极大价值。 展望未来,ClickHouse的多写入架构依然有诸多发展潜力,包括进一步优化路由智能化水平,结合机器学习技术实现动态负载感知与预测路由,或整合更多云原生技术提升多写入集群的弹性和自动化运维能力。同时,社区和企业可共同推动更多相关插件和工具的开发,丰富多写入生态,降低整体系统复杂度。 Tinybird团队通过该架构的成功实践展示了以简洁设计为前提,注重系统安全性和稳定性的技术路线,为大数据实时摄取和分析领域树立了标杆。在数据量持续爆发增长和多样化业务场景的双重驱动下,ClickHouse多写入架构必将成为数据基础设施优化的关键方向之一。企业拥抱并深入应用这一架构,可充分释放数据价值,支撑未来智能化决策和业务创新。
总之,ClickHouse多写入架构通过路由规则的静态配置结合高效的负载均衡组件,实现了实时摄取系统的水平可扩展和高容错。该架构克服了单实例写入瓶颈,满足了亿级事件实时写入的需求,助力企业数据平台在复杂业务环境中保持高性能和稳定性。选择并实施多写入设计,正是迈向下一代大数据实时洞察平台的重要一步。