随着人工智能和大语言模型的迅速发展,越来越多开发者希望能在本地环境特别是个人设备上对强大的模型进行微调训练,以满足个性化需求。传统观念认为要运行和训练像Mistral-7B这样拥有数十亿参数的模型,必须依赖昂贵的NVIDIA GPU和CUDA环境。然而,苹果M系列芯片凭借其强大的统一内存架构和Metal性能着色器(MPS)支持,为Mac用户带来了另一种可能性——在不借助云端计算资源的情况下进行大语言模型的本地微调。本文详细讲述了一位Mac用户如何利用Axolotl工具和LoRA(低秩适配)技术,在M3 Ultra芯片的Mac上,克服多重技术障碍,成功对Mistral-7B进行Rust语言编程领域的微调训练。文章还涵盖了从环境准备、代码实现、错误排查、模型权重合并,到最终模型优化和在本地LM Studio平台运行的全部过程,旨在为类似背景和需求的开发者提供切实可行的指导和思路。传统的LLM微调受到CUDA生态圈的限制,许多最优化工具如bitsandbytes不支持macOS,特别是苹果芯片的MPS后端仍处于不断完善阶段,部分功能如混合精度训练尚不完全成熟。
作者在最初尝试用Axolotl进行微调时便遭遇了安装失败、代码调用错误、数据格式不匹配等问题。Axolotl本身的设计中隐含许多针对NVIDIA GPU的假设,导致在Apple Silicon环境中产生了诸多兼容性障碍,例如bitsandbytes不支持导致的量化优化不可用,以及模型合并步骤中因transformers库对Mistral模型的merge_and_unload方法未实现而引发的崩溃。这些问题逼迫作者放弃了一键式工具,转向编写自定义训练脚本以实现更高的灵活性和透明度。自定义方案主要依赖Hugging Face Transformers库和PEFT(Parameter-Efficient Fine-Tuning)框架中的LoRA技术。通过加载原始Mistral-7B模型,并将其迁移到MPS设备上,作者能够利用苹果GPU加速推理和训练。针对微调任务,最终选择在16位或32位精度下训练,避免使用不兼容的8位化技术。
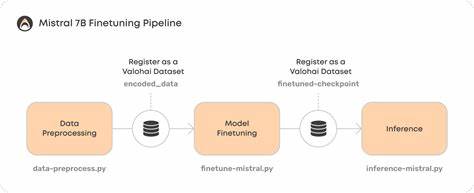
在数据处理方面,作者将Rust专题指令和答案数据集通过适配格式,结合tokenizer完成文本编码,再利用Trainer框架构建训练管道。训练过程中重点设置了较低的批次大小和梯度累积步数来适应Mac的硬件限制,同时关闭了对Weights & Biases的日志记录以减少干扰,禁用了tokenizer并行加速警告,从而保证训练过程顺畅且日志清晰。获得训练完毕的LoRA adapter后,作者自主实现了一步关键操作——将LoRA微调权重合并回原始模型。原始Axolotl方案因API接口不匹配而失败,而使用PEFT提供的merge_and_unload方法可顺利完成该环节,同时借助安全序列化(safetensors)保留了高效且安全的模型存储格式。完成权重合并后,模型被导出为FP16精度文件,后续通过权威的llama.cpp工具链将其转换成GGUF格式,实现4位量化,极大缩小模型体积,便于CPU推理环境下运行。至此,该Rust专用Mistral-7B模型成功实现了本地低成本高效部署。
在Mac端,作者将转换好的GGUF模型置于LM Studio默认识别的目录结构中,实现模型的快速加载和人机交互体验。LM Studio作为苹果友好的LLM前端不但支持GPU加速,还支持多种量化模型,提升了普通Mac用户的运行流畅度。本文总结了工程经验与最佳实践,强调环境隔离、依赖包版本控制、数据格式对应的严谨性、工具的局限性认知与规避技巧。作者强烈建议同类开发者经常关注PyTorch MPS支持的迭代进展,善用PEFT灵活的API接口,并合理规划不同模型文件存放目录避免混乱。此外,禁用无用日志和并行警告能带来更清洁的训练环境。尽管目前苹果芯片生态对LLM训练支持尚不完美,但通过自定义代码绕开CUDA绑定限制,仍能完成较大规模模型的微调任务。
展望未来,随着更多开源工具和库对Apple Silicon优化逐步完善,Mac上本地训练高质量大语言模型的门槛将持续降低。总结而言,通过这次从Axolotl的尝试到自写PEFT脚本再到模型格式转码,本项目不仅证明了Mistral-7B能在Mac上被成功微调,还为同样手握苹果设备且对Rust编程有深度需求的开发者树立了可借鉴的范式。结合本地存储和开源推理框架,用户将无须依赖云端服务即可享有安全、快捷且关联度高的智能编程助手。未来期待相关生态提升带来更多无痛集成方案,助力更多高效模型定制,极大丰富Mac用户人工智能创作的想象力和实践力。