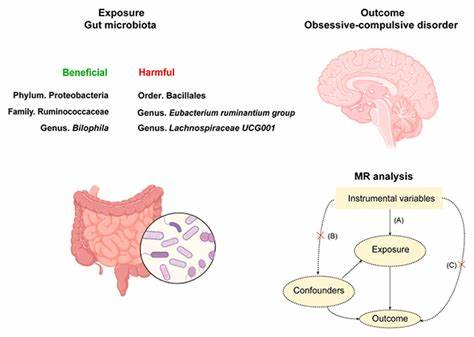
正则表达式是描述字符串集合的强大工具,从简单的字符匹配到复杂的模式识别,广泛应用于搜索、替换和数据验证。然而,现实中许多编程语言如Perl、Python、Java、PHP和Ruby所采用的正则表达式引擎普遍使用递归回溯算法,虽然灵活易用,但在某些复杂或“病态”模式下表现出极其低效的性能,甚至导致匹配时间呈指数级增长。反观上世纪70年代起形成的部分Unix工具如awk和grep,采用了基于有限自动机(Finite Automata)的方法,实现了线性时间的匹配性能,极大地节省了计算资源。正则表达式的匹配问题,归根结底可以用数学上的正则语言理论加以描述和解决,其中有限自动机扮演了关键角色。乔治·肯·汤普森(Ken Thompson)于1968年提出了将正则表达式转换为非确定性有限自动机(NFA)的高效算法,这一算法不仅理论优雅,而且实践简单,代码量不到400行的C语言实现便能展现惊人的匹配速度。汤普森算法构建的NFA将正则表达式拆解成状态节点和连接它们的转换箭头,包含明确匹配字符和空转移。
匹配过程通过模拟NFA在输入字符串上的状态集合转移,利用多状态并行处理有效避免了回溯的重复计算。这种模拟不像递归回溯那样反复尝试不同路径,而是同时追踪所有可能的状态,确保每个输入字符只扫描一次,从而避免指数爆炸。相比之下,回溯算法在存在大量选择分支时需反复尝试各种方案,输入字符稍长或表达式稍复杂即面临性能崩溃风险。文章中以表达式a?nan对字符串an进行测试为例,回溯匹配随着表达式长度增长时间呈指数级扩张,而基于汤普森算法的NFA模拟保持微秒级计算时间,速度差异可达百万倍之多。现实编程场景中,虽然不会总遇到“病态”正则表达式,但低效匹配会在文本解析、日志分析、数据挖掘等关键任务中拖慢执行速度,带来不必要的资源浪费和用户体验下降。有限自动机的另一重要形式是确定性有限自动机(DFA),其特点是在任意状态下对每个输入符号只有唯一下一状态,可以实现更快的匹配流程。
传统方法为NFA到DFA的转换会导致状态爆炸,内存占用剧增,但文章介绍了在溪流计算(on-the-fly construction)基础上的编译和缓存策略,实现了DFA构建与匹配的均衡方案,有效降低了生成成本和内存消耗。通过动态构建和缓存DFA状态,只在必要时计算下一状态,避免了预先生成完整状态集的高昂代价。现代正则表达式中的挑战还包括支持丰富语法扩展,比如字符类、计数重复、多分组捕获、非贪婪操作以及断言等,这些功能为表达和提取复杂文本结构提供了便利,但在实现上需更多巧思。汤普森算法虽起初未涵盖子匹配提取,但经过后续研究和实践证实,其机制可扩展支持匹配组边界追踪,保持整体线性或近似线性复杂度。而针对不规则特性最典型的回溯必需功能——反向引用(backreference),当前尚无实用的高效算法,因其本质超出了正规语言范畴,需特殊处理。实际开发中,设计合理的正则表达式,避免滥用反向引用和复杂的分支结构,会显著提升性能。
同时,优先选择基于自动机的匹配引擎,比如GNU grep、awk或自定义NFA/DFA实现,则更能保证匹配的稳定速度和可预期性。随着文本处理的需求不断增长,特别是在大数据、自然语言处理和系统日志分析领域,高效正则表达式匹配显得愈发重要。通过采用数学严谨且实现简洁的有限自动机方法,彻底改变以往依赖回溯搜索的性能瓶颈,为编程语言和文本工具提供更可靠的底层支持。汤普森所创的技术不仅是一段历史,更是现代软件技术优化的典范,充满启发意义。对开发者而言,理解自动机理论背后的原理,并结合实践中的优化方案,将有效提升编写和调试正则表达式的技能,避免陷入速度陷阱。未来,期待更多语言和库能够采纳此种高效算法,辅以现代内存管理和并行处理,实现更快速、稳定且功能丰富的正则表达式匹配解决方案,满足复杂数据时代的广泛需求。
。