随着人工智能和大数据技术的飞速发展,海量向量数据的存储与检索成为瓶颈。向量嵌入作为表征文本、图像和其他多模态数据的重要手段,其高维特性导致存储和计算资源消耗巨大。如何在保证检索效率和准确度的前提下,有效降低向量数据的内存占用,成为学术界和工业界亟待解决的核心问题。最近,一种基于维度感知的量化方法引起广泛关注,通过非均匀压缩技术实现了超过600%的内存占用缩减,为向量相似度搜索注入了新的活力。该技术代表了向量压缩领域的重要创新,推动了大规模向量数据库的可持续发展。 传统的向量量化方法如乘积量化(Product Quantization,PQ)广泛应用于高效向量检索,利用低位编码替代浮点数据以减少存储。
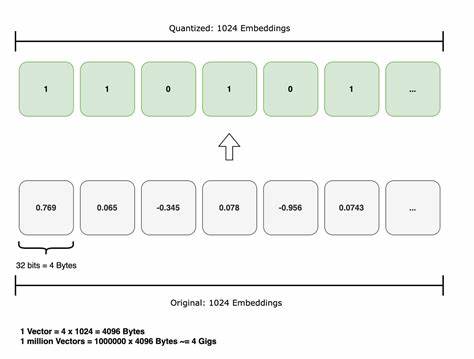
然而,均匀对待所有维度的策略未能充分挖掘各个维度的统计特性,导致信号丢失和搜索准确性下降。新兴的维度感知量化方法通过分析向量维度的统计相关性,自适应地为不同维度分配压缩资源,有效平衡压缩率与精度。其核心思路基于协方差矩阵的特征值分解,将向量各维度划分为高、中、低方差三类,针对不同类别采用差异化编码策略。 具体而言,高方差维度代表了数据中关键信息,采用精度较高的乘积量化保存,以维持对最重要特征的表达能力。中方差维度使用迭代量化(Iterative Quantization,ITQ)技术,利用一位编码实现粗粒度压缩,减少内存开销,同时保留一定的有用信息。低方差维度则被舍弃,认为其贡献较小且噪声较多。
这种多层次、多策略的量化框架使整体向量压缩率大幅提升,同时维持约85%的搜索准确度。实验结果显示,相较于传统PQ方法,维度感知量化技术可实现高达6倍的压缩比,显著减轻存储和计算负担。 该技术得益于先进的维度统计分析能力。通过计算训练数据协方差矩阵,提取特征值作为各维度的统计相关指标,量化过程基于科学的方差划分,避免了简单均匀量化带来的信息浪费。这种基于数据本身分布特性的智能压缩方式,不仅提升了压缩效率,也强化了对核心信号的捕捉能力。对于大规模向量库而言,减小内存占用直接降低硬件成本,提升高速缓存利用率,同时减少IO开销,极大地优化了检索延迟和吞吐量。
在实际应用场景中,维度感知量化技术表现尤为突出。推荐系统通常需要对用户和商品特征向量进行快速相似度计算,以实现个性化精准匹配。传统压缩技术若导致准确性下降,可能引发推荐效果受损。而利用该方法,商业应用可在保持推荐质量的前提下,大规模部署向量索引,满足亿级或更大规模的用户需求。语义搜索领域借助此技术,将向量空间控制在更紧凑的格式中,提升系统并发能力和检索速度,支持复杂的自然语言查询。 此外,边缘计算和物联网设备因受限于存储和算力,更加依赖高效的向量压缩策略。
维度感知量化通过极大降低内存占用,使得嵌入向量能够被轻松部署在移动设备、传感器和智能摄像头等终端,推动边缘AI的普及和推广。尤其是在网络带宽受限的场景下,将压缩后的向量通过通信通道进行传输,也有效缓解了数据传输瓶颈。 技术实现方面,这套维度感知压缩方案作为开源项目Jecq的核心亮点,被设计成Faiss库的无缝替代品。用户无需彻底重构已有向量搜索系统,通过替换底层索引模块即可受益于大幅度的内存节省和计算加速。Jecq采用C++开发,专注于CPU架构,具备跨平台和易集成的特性,配套Python接口满足快速原型和生产环境需求。内置的超参数优化工具帮助开发者自动调节不同维度方差阈值及量化权重,实现最优的压缩与准确性平衡。
行业专家指出,向量嵌入量化的未来趋势是更加智能和自适应。结合机器学习和统计分析技术,压缩算法将能动态捕捉数据变化,调整维度权重,甚至实现在线更新。维度感知策略作为其中的重要分支,已展示了强劲的潜力。预计在语义理解、图像识别、自然语言处理等多模态领域将得到广泛应用,尤其是在需要实时或近实时响应的AI系统中,提高效率的同时保证推理质量尤为关键。 目前,该技术的不足之处在于尚未支持GPU加速,这在面对更大规模向量库时或对速度要求极高的场景会带来一定限制。同时,算法本身依赖于协方差矩阵的准确计算,对于数据分布极端多样或异常情况的适应能力仍需进一步提升。
未来版本中,预计将考虑结合深度学习方法,增强非线性特征的提取与压缩。 总结来看,维度感知的向量嵌入量化技术代表了向量搜索领域的一次质的飞跃。凭借合理的统计理论指导和创新性的编码设计,成功实现了超过600%的内存占用缩减,使得向量数据库能够更高效、更经济地服务于各类智能应用。无论是企业级推荐引擎,还是边缘设备中的轻量级AI推理,该技术均有着巨大的应用潜力。随着技术的不断完善和生态的逐步成熟,期待它在未来的智能信息处理领域发挥更大作用,引领向量计算走向更高效、精准的新纪元。