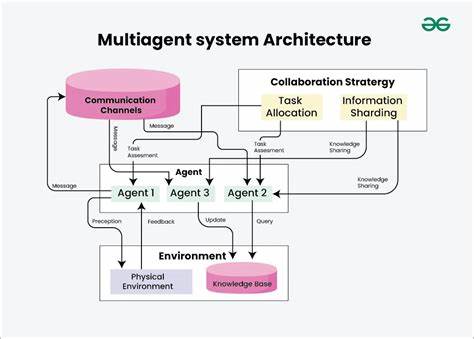
在现代电子设计自动化领域,电路的验证效率直接关系到芯片设计的成本和上市时间。随着电路复杂度急剧增加,传统基于CPU的寄存器传输级(RTL)仿真工具逐渐暴露出性能瓶颈,难以满足日益增长的验证需求。虽然FPGA加速器在某种程度上缓解了这一困境,但高昂的硬件成本和操作门槛限制了其广泛应用。近期由北京大学团队提出的GEM——基于GPU加速且受到仿真器启发的RTL仿真方法,展示了一种兼顾性能与成本优势的创新方案,引起了业界的广泛关注。GEM代表了电路仿真领域迈向GPU计算的新标杆,既解决了传统GPU仿真难以克服的并行执行障碍,也实现了高达64倍的加速效果,为高性能电路验证带来了新的可能性。传统RTL仿真主要依赖CPU串行或多线程处理,其核心挑战在于电路逻辑本质上的不规则性和多分支条件,导致CPU资源难以充分利用。
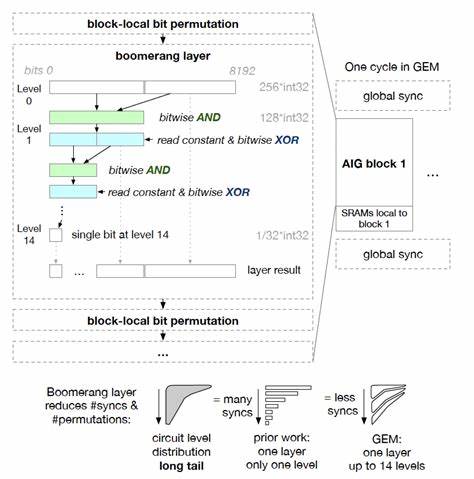
FPGA仿真器虽然能够大幅提升仿真速度,但开发周期长且设备成本高,限制了中小型团队的使用。早期尝试利用GPU加速RTL仿真遭遇了巨大的技术难题,尤其是GPU采用SIMT(单指令多线程)架构,其对执行路径和内存访问的高度统一性要求与RTL设计天然异构的控制逻辑发生冲突,造成线程发散和访问不规则,最终无法发挥GPU计算密集型的优势。GEM的核心创新在于引入一种虚拟超长指令字(VLIW)架构,专门针对电路仿真中的多样化控制与数据流进行设计。这一架构基于深度分析电路逻辑结构,采用类比FPGA设计流程的映射步骤,能够将复杂的电路逻辑转化为适合GPU并行执行的指令流。通过这种方式,GEM有效避免了线程分歧和内存访问冲突,实现了GPU的高效利用。同时,GEM设计了一套专用的CUDA执行流,保障了计算过程的灵活调度和数据共享,进一步提升了仿真吞吐量。
GEM平台具备多方面优势,首先是显著的性能提升。相比于目前主流CPU仿真器,GEM实验中最高达64倍的加速效果极大缩短了设计验证周期,支持更大规模、更高复杂度的集成电路仿真任务。其次,系统基于通用GPU硬件,避免了FPGA加速器的高昂投入和复杂维护,使得中小型设计团队和学术机构也能负担得起高性能仿真服务。此外,得益于架构的灵活性,GEM能够适配多种电路设计和验证场景,支持多种设计语言的RTL代码,进一步拓宽了其应用范围。作为2025年设计自动化大会(DAC)接收论文,GEM不仅技术创新独特,还获得了评审委员会的高度认可,同时荣获最佳论文奖提名,彰显了其在学术与实践领域的双重价值。对于未来电路设计自动化行业,GEM的出现预示着GPU加速仿真将成为主流方向之一。
随着GPU硬件性能的持续提升及专用加速架构的完善,电路验证的速度瓶颈有望被彻底打破,这将极大推动复杂芯片设计的发展循环,促进新一代高性能计算、人工智能芯片快速迭代。开发者和工程师可通过公开的GitHub代码资源快速上手GEM,结合自身具体设计需求进行定制与优化,加速自身研发效率。总而言之,GEM项目以其独具匠心的架构设计和实用的执行流程,成功破解了GPU上进行异构电路逻辑仿真的难题,开拓了一条高性能、低成本的RTL仿真路径。面对不断增长的电路复杂度和快速迭代需求,GEM为电子设计验证领域注入了新的技术动力,也为后续相关研究提供了宝贵的借鉴与启示。随着行业进一步探索基于GPU的仿真优化方法,未来电路验证效率的提升将变得更为可期。