随着人工智能技术的不断进步,语言模型在自然语言处理领域展现出强大能力,尤其是在文本生成、机器翻译、问答系统等多种应用场景中表现突出。然而,尽管这些模型不断刷新性能记录,一个严重制约其广泛应用的问题依然存在 - - 幻觉现象。所谓"幻觉",指的是语言模型在回答问题或生成内容时,给出自信但实际上错误、不准确甚至完全虚假的回答。这样的结果不仅损害了模型的实用价值,也造成用户对人工智能系统的信任危机。 幻觉现象的持续存在并非偶然。研究指出,语言模型之所以产生幻觉,核心原因在于训练和评估机制的设计本身。
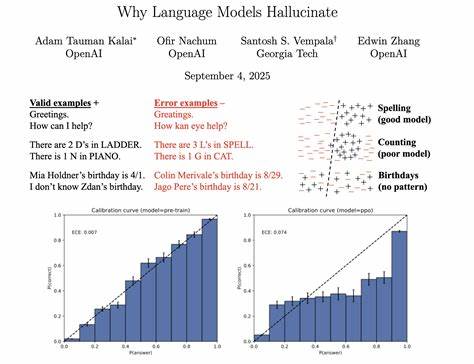
简言之,模型在面对不确定的信息时,倾向于猜测而非承认未知。这与学生面对考试难题时盲目猜答案的行为有异曲同工之妙。训练过程中,模型被奖励的是"正确"的答案,而非诚实地表达不确定性,导致模型学会在缺乏足够信息时仍试图给出一个合理的解释。 更深层次的解释来自统计学视角。语言模型的核心任务是将输入映射到输出的概率分布,其本质是二分类问题。训练数据中包含大量的事实性信息以及误差(包括那些难以辨别的错误陈述)。
当模型无法区分错误信息与真实事实时,误判的概率自然提高,这种统计误差最终表现为幻觉。换言之,如果错误的答案和正确的事实在训练数据和输入提示中难以区分,模型就会在预测时偶尔发生偏差而输出错误内容。 此外,评估标准和奖励机制的设计也强化了这种问题。目前主流的语言模型评测体系极其依赖传统的准确率指标,而这些指标往往鼓励模型必须给出一个具体的答案,即使模型本应保持谨慎或指出不确定性。这种"逼答"机制无形中增加了模型产生幻觉的频率。因为猜测一个可能正确的答案,从策略上讲往往比承认不知道更容易获得高评分,这导致模型在不确定的情况下倾向于冒险回答。
幻觉问题不仅仅是语言模型本身的技术缺陷,更是整个AI训练、评估以及应用体系的挑战。它影响了用户对模型输出的信赖,尤其是在医疗、法律、金融等对准确性要求极高的场景,幻觉可能引发严重后果。用户若无法区分模型"知道"的信息与"猜测"的内容,势必削弱对AI技术的依赖与接受。 为了解决这一问题,业内专家提出了多种应对策略。首先,模型训练应引入区分"已知事实"和"不确定信息"的机制,让模型学会在不清楚答案时坦诚表达不确定,而非盲目猜测。其次,评估和奖励机制需要改进,减少对盲目回答的鼓励,更多地支持模型展现推理过程以及不确定性的信息输出。
这样不仅能有效降低幻觉率,也能提升模型的透明度和可信度。 另一个重要方向是在数据质量上下功夫。加强训练数据的准确性和多样性,清除误导性或错误信息,减少模型学习过程中的噪声,有助降低发生幻觉的可能。结合人类专家的监督和反馈,辅以更严格的验证机制,能够进一步提高模型的事实核查能力。 尽管挑战巨大,随着理论研究和技术创新的推进,幻觉问题正在被逐步破解。未来的语言模型预计将更好地处理不确定性,提升对事实与虚假信息的辨别力,增强输出的可靠性和透明度。
同时,模型的设计理念也将从单纯的"答题机器",转型为具备自我反思和表达信心水平的智能系统。 总结来看,语言模型幻觉的产生是一个多因素交织的复杂问题,既源于统计学的误差特性,也受到训练和评估机制的影响。解决此问题需要技术、规范与伦理多方面共同努力,推动更科学合理的训练策略和评测标准,提升AI系统的可信度。只有这样,语言模型才能真正成为可靠的智能助手,被广泛应用于各行各业,服务于人类社会的发展与进步。 。