随着大规模语言模型(LLMs)的兴起,人工智能技术迎来了新的发展机遇。这些模型因其强大的通用能力,广泛应用于文本生成、问答系统、机器翻译等多个领域。然而,要使这些通用模型更好地适应具体任务,传统的做法往往依赖于昂贵且耗时的微调过程,需要大量标注数据和复杂的超参数调试。面对这一挑战,Text-to-LoRA(简称T2L)技术应运而生,为实现即时且高效的模型任务自适应提供了全新的解决方案。Text-to-LoRA是一种基于自然语言描述,能够即时生成任务特定微调模块LoRA的创新技术。LoRA,全称低秩适配(Low-Rank Adaptation),是一种参数高效的微调方法,通过在预训练模型参数基础上加入低秩矩阵变化,实现模型针对新任务的快速调整。
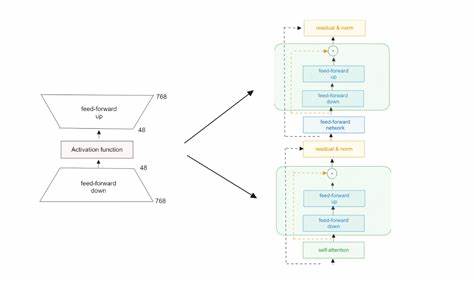
传统的LoRA适配器训练依赖于目标任务数据,且需要针对每个任务反复进行细致调优,这不仅加重了计算负担,也显著限制了模型的应用灵活性。Text-to-LoRA的核心思想是通过训练一个超网络(hypernetwork),能够根据输入的自然语言任务描述,快速合成相应的LoRA适配器参数。换言之,用户只需用人类可理解的语言描述想要的任务,T2L即可即时生成对应的LoRA模块,使得原有模型马上适配新任务,无需传统的训练流程。这种方式有效压缩了任务适配器的存储需求,可同时管理数百个任务适配器实例。更重要的是,T2L具备零样本泛化能力,能够为未见过的新任务即时生成适合的LoRA适配器,极大地提升了模型在动态和多样环境中的实用性和响应速度。从技术实现角度来看,T2L的超网络经过大规模训练,吸收了多种任务LoRA适配器的结构和参数特征,使其能够理解并映射自然语言描述到低秩参数矩阵空间。
这种结构不仅保证了LoRA的低秩特性,也确保了新生成适配器在原模型上的表现与专门训练的任务适配器相当。实验结果表明,T2L生成的LoRA适配器在语义理解、复杂推理等核心任务上,性能能够媲美传统微调方案,并且适配过程仅需一次前向计算,极大降低了计算成本。Text-to-LoRA的出现,为企业和研究机构提供了一条无需高成本训练即可实现大规模模型功能自定义的路径。用户无须拥有大量标注样本或专业调参经验,只凭任务描述,就能得到模型定制解决方案。这不仅缩短了模型部署周期,也降低了算法工程师的门槛,为AI民主化铺平道路。在应用层面,T2L技术适用范围广泛。
无论是金融领域的风险分析、医疗领域的临床诊断辅助,还是教育行业的个性化教学内容生成,只要有明确的任务描述,T2L都能帮助手头的通用模型迅速转化为高效的专业助手。此外,T2L的快速微调优势也助力边缘计算和移动设备应用场景,使得大型语言模型不再局限于数据中心,用户端即可实现灵活智能功能。面对未来,Text-to-LoRA仍有广阔的研究与发展空间。如何进一步增强超网络对复杂任务描述的理解能力以及提升生成LoRA的稳定性,是重要的技术命题。结合多模态输入,融合视觉、语音等多种信息的任务描述,将扩展T2L在跨领域AI适配中的潜力。总的来说,Text-to-LoRA引领了Transformer模型适配的新趋势。
它打破了以往任务训练和模型微调高成本的瓶颈,实现了通过自然语言即时生成特化模型的理想愿景。随着技术的不断完善和推广,T2L有望推动AI模型向更智能、高效、普惠的方向迈进,开启人工智能应用的新纪元。