随着云计算和容器化技术的普及,越来越多的应用被部署在容器环境中,尤其是在Kubernetes集群中。容器的资源限制为系统提供了稳定性保障,例如限制内存上限可以防止应用因内存泄漏导致整个节点崩溃。然而,内存限制带来的不仅是保护,更潜藏着一系列潜在的性能隐患,其中内存阻塞 - - "agony before OOM" - - 便是最令人痛苦的现象之一。 传统观念认为,当应用内存泄漏超出限制时,系统会通过OOM Killer直接终止该进程,容器被强制重启,一切回归正常。然而,现实情况远比理想复杂得多。内存分配失败并非瞬间发生,内核反而会试图回收cgroup内的内存资源,这种回收耗时不少,使得应用在最终被杀死之前处于一种严重迟滞状态。
应用的性能不再是平稳的波动,而是缓慢下滑,响应时间飙升,带来用户体验极大下降。 内存阻塞带来的性能问题对运维和开发团队来说极具挑战性。通常监控系统只记录内存使用量,一旦内存曲线接近边界,报警设置才会触发。但这时往往已经为时过晚,因为性能阻塞阶段已经持续了很久。应用不一定会立刻崩溃,但用户已经感受到明显的延迟和故障。如何更早地捕捉和诊断这场"内存折磨"成为关键所在。
Linux内核引入的压力阻塞信息(Pressure Stall Information,简称PSI)为我们提供了一个强有力的监控工具。PSI能够准确反映进程等待资源分配的时长,对于内存压力的监控特别重要。根据PSI指标,我们可以区分一些进程经历内存阻塞和全部进程受阻,从而判断系统当前的内存紧张程度。 借助cgroup v2的功能,每个容器都能独立地获取自己的PSI数据,从memory.pressure文件中读取到的时间数据表示进程因内存分配等待所阻塞的微秒数。系统会以10秒、1分钟、10分钟的滚动平均时间呈现,运维人员得以清晰了解内存阻塞的趋势和强度。 对容器微服务架构尤为重要的是实时监控和告警。
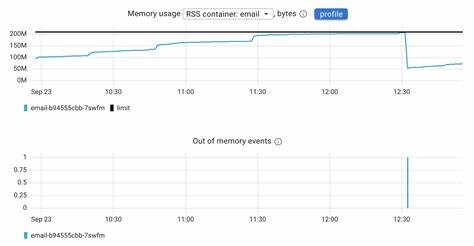
比如用Coroot这类工具,直接导出每个容器的PSI总阻塞时间,并基于阈值(例如内存阻塞超过20毫秒每秒)自动触发警告。这种方式极大地缩短了从问题发生到发现的时间,避免了应用用户体验遭受长时间的"慢死",实现了更智能的根因分析。 在实际使用案例中,一家电子邮件服务部署的容器被限制为200MB内存。最初应用运行正常,但随着内存使用攀升,整体延迟开始急剧上升。可惜的是,由于缺乏内存阻塞的可视化指标,团队无法及时发现问题的本质。容器最终虽然被OOM杀死并重启,但前后已有长达22分钟的极度降级状态,造成大量请求超时和服务中断。
透过PSI指标,团队成功识别了应用在被杀死前的阻塞阶段。由此得出重要结论:OOM杀死过程并非"骤然闪断",而是经历了漫长的"挣扎"阶段。改进监控体系,纳入PSI数据,实现对"痛苦之前"的精准感知,让团队能够提前优化代码、合理调整内存请求或扩容容器,从根本上避免此类问题。 此外,结合eBPF等现代技术对Node.js事件循环以及其他关键部分进行实时跟踪,更加细粒度地了解应用的内存操作行为和潜在瓶颈,为定位和优化提供了丰富线索。 面向未来,随着容器应用复杂度持续提升,传统单纯依赖内存使用峰值的告警体系显然难以满足高可用需求。集成PSI指标的监控方案,成为观察内存压力状况的必要手段。
借助AI辅助的根因分析,定位内存阻塞根源,甚至预判OOM风险,将是提升运维自动化水平和应用可靠性的关键之一。 总结来看,内存阻塞是容器环境中常被忽视,但极具破坏性的"前奏曲"。深入理解内核PSI指标的意义,及时将其纳入监控管理体系,既能提升对内存瓶颈的感知和响应能力,也为构建稳健弹性的现代云原生架构打下坚实基础。未来,围绕内存阻塞的监控和优化必将成为每个云原生团队不可忽视的重要环节,帮助他们跨越OOM的痛苦,迈向更加稳定高效的应用部署新时代。 。