随着人工智能技术的不断进步,构建能够真实理解和预测物理世界的智能体成为科研领域的重要目标。Meta AI最新发布的V-JEPA 2世界模型,以其卓越的视觉理解、动作预测和零样本机器人规划能力,成为推动先进机器智能(AMI)迈向现实的重要里程碑。本文将深入探讨V-JEPA 2的架构设计、训练流程,以及其带来的重要科研资源,包括三大创新性视频物理推理基准,助力学术界和工业界加速突破物理世界理解的难题。 理解世界模型的意义不可忽视。人类之所以能够灵活应对生活中的各种复杂情景,离不开内心强大的世界模型。这种模型使我们能预测物体运动、场景变化,推断潜在因果关系,从而指导合理行动。
例如,投掷网球时,我们直觉上预判球体会受重力影响下落,而不是突然改变轨迹。又如不同场景中的物理交互,无论是运动中的曲棍球还是厨房烹饪,背后都依赖着对物理规律深刻的认知和对未来状态的推演。 构建具备类人物理直觉的AI,需要模型能够高效地实现理解、预测及规划三大核心能力。理解涉及识别视频中物体、动作、运动等语义信息。预测不仅是对未来场景的演变作出推断,还包括对智能体特定动作带来变化的推测。规划能力则在此基础上,帮助AI连续制定行动策略,完成指定目标。
通过训练这样具备内在世界模型的AI,我们期待实现能够自主思考和适应新环境的智慧机器人和智能系统。 V-JEPA 2(Meta Video Joint Embedding Predictive Architecture 2)是Meta AI继2022年首发JEPA之后,发布的基于视频数据的高级世界模型。该模型包含12亿参数,采用联合嵌入预测架构,主要包括编码器和预测器两个部分。编码器负责从原始视频中提取高语义含量的状态嵌入,以捕捉所观察场景的核心信息。预测器则基于当前嵌入及上下文信息,对未来状态的嵌入进行预测。 训练阶段分为两步。
第一步是无动作预训练,使用超过一百万小时的视频及一百万张图片,涵盖丰富的场景和交互信息,帮助模型学习物体间动态关系和人与物体的互动规律。在这阶段,V-JEPA 2就已展现了强大的动作识别和未来动作预测能力,如在Something-Something v2和Epic-Kitchens-100等动作识别与预期任务上表现出色。此外,将V-JEPA 2编码结果与语言模型对齐后,更实现了视频问答任务中的领先成绩。 第二阶段是动作条件训练,专注于机器人领域的视觉数据和对应控制动作。通过加入机器人执行的具体动作信息,预测器学习考虑动作对未来环境状态的影响,提升了模型在机器人规划和控制方面的实用价值。令人震惊的是,尽管机器人领域数据有限,仅62小时的动作条件训练就足以让模型具备出色的零样本机器人规划能力。
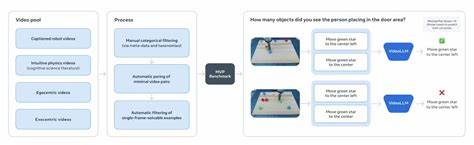
利用V-JEPA 2,Meta演示了在无人演示和新环境下的机器人任务执行能力。该模型可实现抓取、移动和放置陌生物体,并通过视觉目标图像引导机器人规划连续动作轨迹。短期任务通过模型预测多个候选动作后依照最接近目标状态的方案执行,实现动态调整和控制。更复杂的长时间任务则分解为系列视觉子目标,类似人类的视觉模仿学习,模型成功率可达65%至80%。 为了推动社区交流与进步,Meta同时推出了三大视频物理推理基准:IntPhys 2、Minimal Video Pairs(MVPBench)和CausalVQA。IntPhys 2专注测试模型区分物理合理与不合理场景的能力,采用生成器创建成对视频,其中一段发生物理异常,模型需准确辨别。
尽管人类测试准确率高达85%-95%,现有模型表现接近随机水平,揭示巨大提升空间。 MVPBench设计巧妙规避以往视频语言模型中常见的捷径问题。其通过最小视觉差异对呈现成对视频和对应反义问题,要求模型在保证答对一个样本的同时也必须正确回答其对应的“极小变化”样本,以此确保模型真正理解物理现象,而非依赖表层视觉或语义线索。 CausalVQA则专注因果推理能力,测试模型对物理世界因果关系的理解。其包含反事实设问、动作预期及计划相关问题,旨在揭示模型在“过去发生了什么”和“未来可能发生什么”之间的推断能力差异。目前大型多模态模型在“发生了什么”问题上表现逐步提升,但在预测未来和规划选择上仍显不足,进一步指明改进方向。
Meta开放了这三大基准的数据及代码(GitHub及Hugging Face平台),同时建立了公开排行榜,便于研究者持续追踪模型在物理理解领域的进展,促进学术和产业界的协同发展。 展望未来,V-JEPA 2的开发团队已明确了进一步探索的重点方向。其一是多时间尺度分层模型,现有模型聚焦单一时间尺度,而现实生活中的许多任务需要跨越多个长短时间维度,如烹饪、家务等复杂流程,未来分层JEPA模型将更好支持此类分阶段规划。 其次是多模态融合,将视觉、听觉、触觉等多种感官信息结合,提升模型的环境感知和物理推理能力。最后,团队也期待共享更多开源资源,鼓励社区在基础模型、训练方法和实际应用中产生创新,促进先进机器智能逐步成为现实。 总的来说,V-JEPA 2作为首个以视频为核心训练素材的高参数世界模型,不仅实现了对物理世界理解与预测新高度,更将零样本机器人规划推向新的实用层面。
三大创新视频物理推理基准为业界提供了评价新标准,揭示重大差距和改进路径。Meta通过开源代码和数据资源,预示着物理推理AI技术更开放、更务实和更精进的未来。借助这些技术突破,未来智能机器人及系统将能更精准地模拟人类物理直觉,广泛应用于工业、家庭和公共场景,为人类生活和生产带来翻天覆地的变革。