在现代互联网应用中,快速高效的数据存取需求日益增长。Redis作为一种高性能的内存键值数据库,被广泛应用于缓存、消息队列和会话管理等场景中。备受青睐的它背后到底有什么核心原理,以及如何从零实现一个Redis类似的键值存储系统?本文将从基础的内存键值存储和TCP服务器入手,揭开Redis克隆项目的第一部分,带你深入了解分布式存储系统的雏形。键值存储作为数据库系统中的一种基础数据组织方式,其思想简洁直观:通过唯一的键标识,将数据以键值对形式存储起来,查询时只需通过键快速定位对应的值。与传统关系数据库相比,键值存储强调速度与简单性,避免了复杂的关系映射和SQL解析,大大提升了访问效率。这也是Redis热门的关键原因之一。
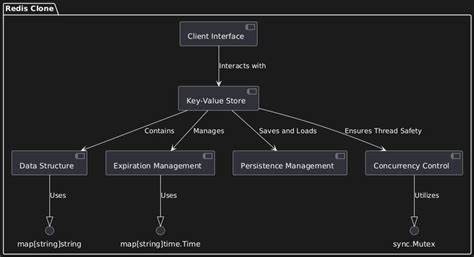
在实现键值存储时,内存结构的设计尤为重要。选择合适的数据结构能够保证读写操作的高效性。本文利用Java中的ConcurrentHashMap作为核心存储结构。该结构不仅线程安全,且在高并发访问场景下表现优异,适合未来扩展多线程操作。通过实现单例设计模式,确保整个应用生命周期内存储实例唯一,有效管理系统资源,降低开发复杂度。在存储层基础建立后,如何让外部应用访问并操作这些键值数据成为关键。
不同于传统HTTP协议,Redis采用的是轻量级的TCP协议通信,去除HTTP内部的额外开销,进一步提升数据处理速度。因此本文也选择搭建基于TCP的服务器,实现与客户端的直接数据交换。TCP服务器主要承担监听端口、接收客户端请求、处理数据并反馈结果的职责。通过多线程设计,每当有新连接进来时,服务器为其创建独立线程,保证并发请求的顺畅处理。接收的请求会经过简单的命令解析模块,识别出诸如SET、GET、DEL等指令,并根据命令参数调用底层存储操作。作为一种简洁且直观的协议,命令解析基于空格拆分输入字符串,对参数个数和格式进行严格校验,确保系统运作的稳定与安全。
当系统接收到“SET name Sushant”类指令时,会将键“name”与值“Sushant”存入ConcurrentHashMap。当收到“GET name”请求时,则返回相应值。若执行“DEL name”则删除对应键值。这样的基本命令满足了键值数据库的核心增删改查需求。系统启动时,主程序实例化KVStore存储类与TCPServer服务类,监听默认端口如6349。用户能通过Telnet等客户端工具,连接至该端口,并发送命令进行交互,体验基于内存和TCP构建的轻量级数据库服务。
虽然该系统尚未实现完整的Redis特性如持久化快照、多节点分布式存储、一致性算法、发布订阅机制等,但这套基础架构为后续设计奠定了坚实的基础。分布式系统的复杂度极高,进入这一领域最重要的是循序渐进的学习和实践。通过自己动手构建一个简易版本,能够快速理解底层实现原理,不断调整改进,最终形成对全栈分布式存储能力的掌握。此外,选择Java进行开发,凭借其稳定的多线程机制和广泛的生态,亦有助于研究和应用分布式通信协议、数据存储引擎及并发编程等重要概念。基于TCP协议通信的设计还将对后续延展诸如多节点集群、数据分片与负载均衡等功能提供便利。简而言之,构建Redis的克隆版本不仅是一次技术挑战,更是探索分布式系统和数据库技术的宝贵实践旅程。
从最简单的内存键值存储开始,逐步搭建通信协议,向分布式高可用和数据持久化演进,都将极大提升开发者的技术储备与解决问题能力。未来,随着项目的推进,围绕一致性算法如Raft、数据分布如一致性哈希、节点间通信如Gossip协议及复杂功能如键过期、发布订阅等内容将陆续展开。关注每一次迭代更新,搭建起属于自己的分布式高性能数据库系统,既是学习成长的过程,也是对技术极限的不断突破。通过反复实践和总结,必将掌握构建现实世界分布式数据库的核心诀窍,成为架构设计和底层实现的双料专家。