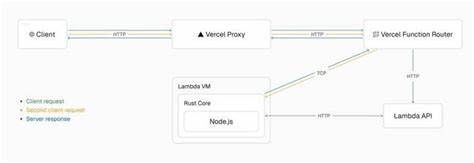
随着数据驱动时代的到来,数据库系统在处理复杂逻辑需求时,用户自定义函数(UDF)逐渐成为开发者扩展数据库功能的首选。然而,传统UDF执行性能低下的情况普遍存在,这不仅限制了其在性能敏感型应用中的推广,还使得许多潜在的创新应用面临阻碍。德国图宾根大学计算机科学系丹尼斯·赫恩(Denis Hirn)博士在其2024年博士论文中,针对这一问题提出了全新的编译方法,极大地优化了复杂UDF的执行效率,为数据库系统注入了强劲的性能动力。用户自定义函数的基本作用是允许开发者在数据库内嵌编写程序逻辑,丰富SQL语言本身的表达能力,使其能够处理更复杂的任务。尽管极具灵活性,传统的UDF往往存在运行缓慢的缺陷,主要源于SQL与命令式编程语言(如PL/SQL)在执行模型上的冲突。命令式语言以逐语句的形式实现逻辑,执行时需要频繁切换数据库核心查询引擎与解释器,形成严重的执行阻力,消耗大量时间和资源。
论文中提出的跳板风格编译方法巧妙地将UDF的循环和递归控制逻辑转换成纯SQL查询表达,使得数据库能够一次性执行整个计算过程。跳板技术本质上通过构造一种“延迟执行”的机制,避免了传统解释执行中的上下文切换,从而彻底解决了SQL执行计划与命令式程序间的结构差异,消除运行时的阻力。此方法的优势不仅在于提升执行速度,更重要的是恢复了数据库查询优化器的主导地位,优化器可以将整个逻辑看作单一查询进行智能调优。该编译策略的通用性也十分显著,因为它依赖于SQL标准特性,如LATERAL连接和递归公共表表达式(CTE),无需依赖特定数据库定制的扩展功能,极大地提升了方法的跨平台移植能力。针对迭代式UDF,研究团队设计了一套包含十八个不同函数的测试集,覆盖多样化编码情境。在实验中,跳板风格的编译方法使得这些函数的执行速度平均提升了三倍,尤其是在具有复杂循环结构的函数应用中表现卓越。
尽管如此,研究也客观地指出部分场景下性能提升有限甚至下降的情况,深入分析表明关键在于SQL查询优化器的处理策略和UDF逻辑转换的具体细节,为后续改进指明了方向。递归UDF的性能瓶颈更加难以克服。以主流数据库PostgreSQL为例,其在调用递归函数时,频繁的解析和规划过程成为性能“瓶颈”。这种重复开销使得递归UDF的运行代价极高,通常超出正常运行时间的九成。本论文进一步将跳板编译方法扩展应用到递归函数场景。使用同样基于SQL递归CTE的技术,将函数递归逻辑重新组织进数据库内置查询执行流程,彻底消除冗余的解析及规划负担。
通过对十个典型递归UDF的实测,跳板编译技术展现了高达180倍的性能提升,极大地激发了递归函数在数据库系统中应用的潜力。这一结果不仅证实了函数编程思想与关系型数据库查询模型的兼容可能,也刷新了学界和工业界对SQL表达力的认知。跳板风格SQL的提出和实践,彰显了SQL不仅具备用于复杂运算表达的能力,也能实现高效执行。该技术为数据库提供了一套切实可行的编译规则,助力开发者将复杂的用户自定义函数编译成能够被数据库优化器完整识别的SQL查询。数据库系统借此可实现选择性优化策略,提升查询响应速度,降低资源消耗,同时保持高度的可移植性。归根到底,该项研究突破了传统对数据库系统内部运算逻辑的局限性,融合了编程语言领域的前沿理念,推动数据库执行模型向更现代、更灵活的方向演进。
这对提升数据库系统支持复杂业务逻辑的能力,促进大数据处理、人工智能应用、复杂事件处理等领域的发展有着深远的影响。随着数据库应用场景日益多元化,复杂的用户定制逻辑成为必然需求。借助跳板编译方法,不同数据库平台均可无缝集成高效UDF执行方案,消除性能瓶颈,释放数据潜能。同时,学术界和工业界合作推动该技术标准化和商业化,将进一步加速其在实际产品中的落地。未来研究方向还包括结合机器学习优化查询计划,自动选择最佳编译参数,提升编译产物的适用性与稳定性。总体而言,改进复杂用户自定义函数编译技术是一条连接传统数据库功能和未来智能数据处理的重要桥梁。
它不仅为SQL语言注入了活力,更为数据库系统的可扩展性和高性能打下坚实基础。借助跳板风格和SQL的强大表达力,数据库开发生态正迎来新一轮的技术革新和应用繁荣。