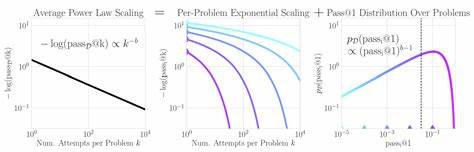
近年来,大型语言模型(Large Language Models,简称LLM)在自然语言处理、数学问题求解、程序辅助证明和多模态任务等领域展现出惊人的能力。这些模型不仅能生成流畅自然的文本,还能在复杂任务中取得高准确率,这背后隐藏的数学规律和性能提升机制,正在成为学术界与工业界极力探索的热点。 一项由Rylan Schaeffer等研究者于2025年发表的研究工作提出了一个令人关注的现象:当模型面对同一问题进行多次尝试时,只要任意一次尝试正确,则该问题即被视为成功解决。研究发现,所有任务的平均成功率的负对数(negative log)与尝试次数呈现出幂律缩放关系。换言之,多次尝试的整体成功率增长并非简单的指数增长,而是表现为一种渐进的多项式增长,这一规律被称为“功率法则”或“幂律规律”。 起初,看似存在矛盾的是,单个任务在多次尝试时,失败率应该以指数速度下降,这符合概率理论的直觉。
然而,整体表现却展现出非指数而是多项式的趋势,这个“聚合”层面的幂律增长究竟如何产生,成为学界亟需解答的谜题。 研究对这一矛盾的关键解释在于任务难度分布的特殊性。具体来说,不同任务之间的单次尝试成功概率呈现出重尾分布(heavy-tailed distribution),极少数异常困难的任务的成功概率远低于大多数任务。正是这少部分极难任务导致整体成功率的聚合表现被“拉伸”,将原本单个任务的指数下降转换为整体的幂律增长曲线。 这一发现不仅帮助理解了大型语言模型在实际环境中的性能增长模式,也能解释此前研究中观察到的偏离功率法则的现象。通过模型内部成功概率分布的调整,可以更精准地预测整体性能提升的速度和极限。
同时,该分布式视角还为推理计算资源的有效利用提供理论依据。研究显示,通过准确把握成功概率的分布特征,可以在减少多达两个数量级的计算资源消耗(或等价节省四个数量级的推理计算)下,实现对功率法则指数的高精度预测。这对于资源有限的实际应用场景尤为重要。 为什么幂律规律在大型语言模型的推理表现中普遍存在?背后深层原理或许源自任务和数据的多样性。现实世界问题不仅种类繁多,复杂度跨度亦极大。模型在面对不同难度的任务时,成功概率差异显著,从而形成了自然的重尾分布。
与单一简单模型不同,大型语言模型天然具备巨量参数和多层次结构,能适配多样的输入信息,不断从尝试中累积成功经验。 此外,上述研究延伸到多模态任务领域,进一步验证了幂律规律的通用性。无论是纯文本任务,还是结合图像、代码等多种模态信息的混合任务,尝试次数与成功率之间的功率法则均成立。这说明该规律不仅是数学上的巧合,而是大型语言模型和推理动态本质的体现。 对于开发者和科研人员而言,这些研究成果带来的启示不可小觑。首先,重视任务分布特性可帮助设计更加鲁棒和高效的推理策略,例如优先聚焦中等难度任务以提升整体效率。
其次,预测推理资源需求不再简单依赖经验或线性估算,而是能基于数学模型做出精准判断,从而节省成本和时间。最后,随着模型与硬件性能持续提升,理解性能扩展规律将助力规划未来多轮尝试和交互式AI系统的设计,提升用户体验和应用范围。 大型语言模型为何能产生如此强大的推理能力,背后不仅是海量数据和参数的堆积,更是隐藏着深刻的统计学和概率论原理。研究表明,单个案例的指数失败率与整体幂律成功率的协调统一,正是理解模型推理性能增长的核心钥匙。 展望未来,结合重尾分布理论与动态推理机制,人工智能研究可能会迈入一个新阶段。优化的多次尝试策略、智能分配计算资源以及多模态融合技术,将使LLM在解决极其复杂、多样化的问题时表现更加出色和高效。
从学术到工业应用,这种对“性能功率法则”的理解无疑将推动大型语言模型向更加智能、自适应且节能的方向发展,满足日益增长的多样化需求。 总结来看,大型语言模型能力逐步提升并非简单的线性或指数规律叠加,而是深受不均匀任务分布影响的复杂动力学过程。单问题指数失败下降与全局幂律成功率增长的统一解释,不仅提供了理论创新,也指引了未来技术发展路线。随着研究不断深化,我们有望窥见人工智能系统如何通过数学法则和概率结构,赋能更加精准和高效的智能推理,树立时代新标杆。