随着社交网络的飞速发展,数据存储与处理面临的挑战也日益严峻。Facebook作为全球最大的社交平台之一,每天需要向十亿以上的活跃用户实时提供数以亿计的个性化内容和交互信息。在2013年,Facebook推出了名为TAO(对象与关联,The Associations and Objects)的分布式数据存储系统,以应对传统关系型数据库和分布式缓存无法完全满足的复杂需求。TAO凭借其图数据模型和优化的系统架构,成为Facebook后端处理社交信息的核心引擎,极大提升了数据访问的效率和系统的扩展性。Facebook最初的数据存储主要依赖MySQL数据库,结合Memcache作为分布式缓存以提升访问速度。然而,这种组合在处理社交网络复杂关系时表现出明显的不足。
传统的关系数据库基于行列存储,擅长结构化查询,但难以高效执行大规模的关联关系遍历和动态图结构操作。同时,Memcache虽然可以加快数据访问速度,但其作为一个简单的键值存储缺乏自动缓存填充和一致性维护机制,给工程师带来了较大的实现复杂度和潜在的故障风险。Facebook工程师因此寻求一种更适合社交网络数据结构的方案,最终基于对象和关联关系构建了图数据模型,并开发了专门的分布式服务TAO。TAO通过将每个用户、帖子、评论、点赞等实体抽象为节点(对象),不同实体之间的各种关系如关注、评论、点赞等抽象为边(关联),实现了对社交图的高效表达。这种图模型天然契合社交网络的结构特征,有利于执行诸如好友推荐、内容聚合等社交算法。TAO的架构设计独具匠心,它采用分层缓存机制,将服务器集群划分为地理分布的多个集群,实现跨地域负载均衡和故障容错。
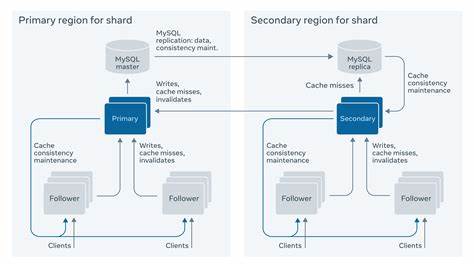
不同于传统数据库单体服务器的设计,TAO通过将对象和关联分别存储和缓存,精细控制数据在内存和持久层之间的流动,提升了读取性能和系统的整体响应速度。请求首先发送到缓存层的“追随者(Followers)”集群,若发生缓存未命中,则向上层“领导者(Leaders)”集群请求数据,后者再与MySQL持久存储交互。这种层级设计有效减少了持久存储压力,同时为缓存一致性维护提供了保障。TAO在数据分片机制上也极具创新性。数据被拆分为数十万片,每片数据(Shard)都存储在同一MySQL服务器上,并缓存于对应集群,实现数据的局部性存储和访问,避免了热点数据造成的系统瓶颈。TAO还支持数据分片动态迁移和克隆,帮助应对突发的访问峰值,保持系统稳定。
对象和关联两类核心数据结构中,每个对象包含类型定义和字段,支持随时新增、修改甚至废弃字段,极大降低了产品迭代中数据库模式变更的复杂度。关联关系支持双向维护,即为某种关联指定逆向类型,系统自动维护关系的双向一致性,非常适合实现好友关系等对称性强的场景。此外,关联关系都带有时间戳,方便系统根据创建时间优化缓存策略,提升热点数据的缓存命中率,满足社交媒体中内容实时更新的需求。TAO的API设计简洁高效,提供创建、查询、更新和删除对象及关联的方法。其查询操作支持点查询、范围查询和计数查询,满足了绝大多数社交平台的访问模式。更复杂的图遍历和模式匹配任务被设计为由客户端通过组合简单查询实现,而非复杂的服务器端操作,充分利用网络带宽和客户端计算资源,实现了性能与灵活性的平衡。
在一致性模型方面,TAO默认采用最终一致性原则,权衡了分布式系统中的可用性和一致性,确保高可用性的同时尽可能保证用户数据的更新能迅速反映。这符合Facebook“始终在线”的服务理念。对于极少数对一致性有严格需求的场景,TAO允许客户端选择更强的一致性策略,尽管这意味着可能的性能损失和可用性降低。TAO的部署环境涵盖多个地理区域,每个区域设置主数据库和备份库,通过MySQL复制实现主备同步。写操作通过追随者集群写入,再逐层同步至领导者集群和持久存储,保证了数据的一致写入和缓存更新。出现单点故障时,系统能够自动将主分片切换至其他区域,保障服务连续性。
TAO的成功不仅体现在其技术架构上,也体现在极大简化了Facebook产品工程师的数据访问操作。借助TAO,工程师无需直接操作MySQL或Memcache,摆脱了传统模式下复杂且易错的双数据存储模型,提升了开发效率和系统稳定性。TAO的出现标志着Facebook从传统关系数据库向现代图数据存储范式的转变,既满足了海量数据实时访问的需求,也支持灵活多变的产品功能创新。总之,TAO充分发挥了图数据库在表达复杂关系中的天然优势,通过细粒度的数据分片、多层次缓存、双向关联维护和优化的时间属性利用,成功驾驭了社交网络数据的庞大规模和高度动态性。它不仅极大提升了Facebook的用户体验和系统性能,也为图数据库在大规模互联网应用上的实践提供了宝贵示范。未来,随着社交网络和用户行为的数据日益复杂,TAO及其衍生技术的持续演进必将继续推动数据基础设施的革新,助力实现更加智能和个性化的社交服务。
。