自从伽利略提出理解宇宙需掌握其语言以来,数学一直被视为揭示自然规律的根本工具。从牛顿的运动定律到爱因斯坦的能量质量关系,数学的表达方式使我们能够精准预测和控制物理世界。然而,将相同的数学范式应用于生物学时,却难以获得彻底的突破。生物系统展现出高度的复杂性、多维交互和变异性,这使得传统数学模型难以完全捕捉生命现象的精髓。机器学习,这一基于数据驱动、非线性分析的技术,正逐渐被视为解锁生物系统奥秘的关键语言。传统数学模型在物理学中因其对线性关系和独立变量的假设而强大,但生物学中的变量高度耦合且非线性,依赖于特定的环境和上下文,使得固定公式难以对应实际生理状态。
例如,在单细胞层面,成千上万的基因和蛋白质相互作用,数量虽庞大但又不适合通过统计平均来简化,且系统间的互联互通更是复杂多样。生物的多样性和不断演变的特质更是对传统模型的严峻考验。因此,科学家们逐渐认识到需要一种能包容复杂性、捕捉动态关系的新方法。表面上看,机器学习也是数学的一种,但它并非像过去那样试图用简洁的方程来描述系统。相反,它利用大量数据训练模型,自动发现内在规律和隐藏的结构。例如,深度神经网络通过成千上万个参数,捕捉生物学中复杂且上下文依赖的非线性关系,从而超越了传统数学模型的局限。
就如同语言中同一个词在不同语境下表达不同意义,生物中的诸多分子也根据环境展现多样功能。以肿瘤抑制蛋白p53为例,在基因损伤时诱导细胞凋亡,而在胚胎发育时又促进细胞存活与生长,传统模型难以同时涵盖这种多面性。机器学习天然适合处理这种高度情境化的信息。生物系统内的信息处理也与机器学习极为相似。细胞通过转录因子这一符号系统对外界环境进行编码,转录因子在活跃与非活跃状态间切换,调控基因表达,从而反映复杂的细胞状态。例如,热休克因子HSF1在细胞感受高温时活化,启动保护蛋白合成,这种生物符号的运作过程与机器学习中向量空间的压缩和抽象表达极为相似。
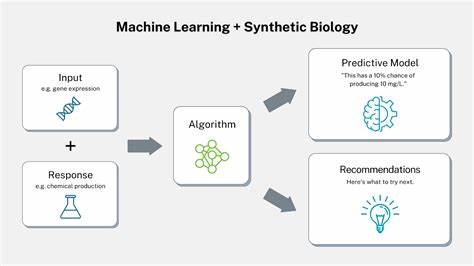
机器学习中的潜在空间概念也揭示了生物学数据隐藏的核心信息,通过降维提取重要特征,帮助科学家直观理解细胞周期、分化阶段或应激反应等复杂生物过程。单细胞RNA测序技术应用机器学习算法,区别细胞类型和状态,揭示传统基于固定标记基因的分类无法发现的生物学规律。机器学习不仅预测生物过程,还推动了“预测性生物学”的兴起。这一学派将重点放在建立能够预测系统行为的模型,而非单纯描述分子功能或互作。细胞自身也更像预测机器,通过内部符号预测环境变化下的最优应答,而非深刻理解外部物理机制。机器学习驱动的预测性生物学使生物工程进入了新纪元,从设计优化蛋白质结构,到调控代谢通路,极大提升了效率和创新能力。
生物学的“混乱性”使得其难以用简单规则和固定类别定义,机器学习却能拥抱这种“不规则”,将变异视为数据,捕捉并利用其内在模式。以基因SOX9为例,其在胚胎性别决定、软骨发育、肠道干细胞维持和癌症进展中的多样作用正是机器学习所能解析的上下文依赖性最好例证。未来的生物工程领域,将越来越多地依赖机器学习辅助设计,突破传统基于物理化学原则的限制,打造复杂疾病精准疗法、环境适应性微生物组以及创新功能生物材料。同时,传统数学与机器学习的结合,如神经微分方程,有望兼顾模型的可解释性和预测性能,为生命科学提供兼具人类认知和机器智能优势的研究工具。机器学习为理解生命打开了另一扇窗,像伽利略发现数学是宇宙通用语言那样,机器学习正在成为生物学的“母语”。随着数据的不断积累与算法的进化,我们对生命本质的认知必将迈上新的台阶,推动医疗、农业、环保等多个领域实现质的飞跃。
。