在软件开发、数据分析、用户体验测试和自然语言处理等领域,经常需要大量英文的姓名数据。无论目标是生成测试用例、填充演示数据库、进行人口统计分析,还是训练机器学习模型,掌握可用的英文姓名数据源与处理方法都能显著提高效率并降低法律与伦理风险。下面汇集了获取、评估、清洗、结构化与合规使用英文名字与姓氏数据的实务经验与建议,帮助工程师、数据科学家与产品经理高效、负责任地使用这些资源。 权威公开数据源与可下载的姓名集 在选择数据源时,优先考虑权威且许可明确的数据集。美国社会安全局提供了最为详细的英文名字历史记录之一,其婴儿名字数据按年、按性别列出名字出现的频次,并且资源可直接下载为文本或CSV格式,适合需要时间序列姓名流行度的场景。美国人口普查局也发布了姓氏频率数据,典型的有1990年与2000年的人口普查姓氏列表,其中包含姓氏的出现次数和种族/族裔分布估计,适合进行姓氏层面的统计与人口学研究。
开放数据集合通常标注了许可信息,社会安全局和美国人口普查局的大多数数据属于公共领域或政府公开数据,使用时应核验具体页面上的许可说明。 开源社区与汇总仓库同样是重要来源。GitHub上存在多个集合英文名字与姓氏的仓库,这些项目往往汇集了不同网站、官方数据与社区贡献,提供CSV或SQL导出。使用这些第三方集合时需要留意来源链与许可,确保数据原始来源的许可允许再分发或用于商业用途。云平台的大型公共数据集也非常方便,例如Google BigQuery的公共数据集中包含按年汇总的美国姓名数据与其他语言或国家的公共信息,借助云查询可以高效提取需要的子集。 数据格式与结构设计建议 要便于后续查询和分析,建议把姓名数据设计为规范化的表结构。
最简单的表包含字段:given_name(名)、family_name(姓)、gender(可选)、year(可选)、count或frequency以及source字段来记录数据来源与许可信息。对于需要保留分地区信息的项目,可以增加state或region字段以存储分地域的出现频率。在需要处理复合姓或带有前缀的姓名时,建议增加raw_name字段以保留原始字符串,便于回溯。 如果打算使用SQL存储,建议为姓和名分别建立索引以提升模糊匹配与前缀查询性能。频率字段可以用来按概率抽样生成更加真实的测试数据。对于需要分级别权重的合成用户名单,使用count或frequency字段计算相对权重,从而在数据生成过程中更贴合现实分布。
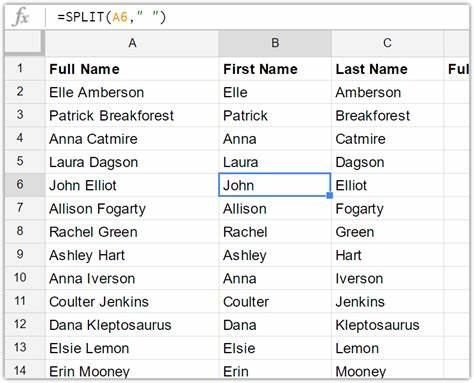
姓名清洗与解析的常见问题 英文姓名看似简单,但在实践中会遇到许多复杂情况,例如复姓、带连字符的双名、包含前缀和后缀(如Dr., Mr., Jr., Sr., III)、含撇号的姓氏(如O'Connor)、以及带有文化或地理特征的多词姓氏(如van der Waals、de la Cruz)。姓名中还可能包含中间名或首字母缩写。处理时应先进行统一的文本规范化,包括去除多余空白、统一大小写、进行Unicode规范化以及决定是否保留或剥离标点与称谓。对真实数据进行拆分和合并时,保留原始字段是最佳实践,这样任何自动化解析出错时可以回溯。 姓名解析建议采用多策略结合的方法。首先使用规则化的分词与常见称谓表剥离明显的前缀和后缀,然后基于空格与连字符进行切分,同时借助姓氏与名的高频列表来判定切分的合理性。
对于模糊场景可以使用概率模型或训练好的命名实体识别模型来提升准确率。解析时应做好异常记录,并在人工审核流程中逐步完善规则集。 性别推断与文化敏感性 很多项目会尝试根据名字推断性别。对于英文名,社会安全局提供的按年按性别的名字频率是一个常见的资源,它能反映某个名字在不同年份的性别倾向。但要明确,基于名字的性别猜测仅是概率性估计,并不代表个人的性别认同。使用性别推断结果时,应在产品和研究中谨慎表述并尊重用户的自我认定。
若产品场景涉及个人资料或决策重要性较高,最好允许用户手动设置或确认性别信息,而不要仅依赖自动推断。 国际化与跨文化姓名差异 英文姓名数据库多数基于英语或美国语境,但真实世界中存在大量移民与多语言姓名。不同文化对姓和名的排列顺序、构成元素有不同习惯。亚洲和东亚文化中姓通常出现在名之前,而西班牙语系常见双姓,葡萄牙语和拉丁美洲国家又有特定的命名规则。处理国际化姓名时,避免过度依赖假定的"名在前姓在后"规则,应提供可配置的解析策略,并在数据模型中留出灵活空间来存储多部分姓名和原始顺序。 隐私、合规与伦理考量 使用真实姓名数据时必须格外谨慎。
即便姓名本身通常不是受严格隐私保护的敏感信息,但与其他标识符结合时可能构成个人识别信息。对于生产环境或对外共享的数据集,应优先使用已明确为公共领域或具有适当许可的数据源。避免在公开演示或教学数据集中暴露真实个人的全部信息,必要时采用去标识化或生成式替换策略。合成姓名数据常常是既安全又实用的选择,特别是在需要共享或开源的场景。 在欧盟等地区,数据保护法规对个人数据有严格规定,对姓名与其他身份信息的处理应遵守当地法律。对于跨境数据处理,需关注数据出口限制与合规责任。
企业在使用第三方姓名数据作为训练集或产品资源时,应进行法律与合规评估,并保留来源与许可证明以备审计。 如何构建高质量的合成本地姓名库 当现成数据不可用或出于隐私考量需要生成测试数据时,可以通过将公开的姓氏列表和给定名列表按真实分布合成姓名来得到可信度较高的虚拟人名。合成过程可基于频率进行加权抽样,以模拟真实世界的名字流行度和姓氏分布。根据产品需求,可以引入地域权重来反映不同州或国家的命名偏好。合成姓名时同时生成与之不具识别性的附加信息,如随机化的年龄段、模糊化的地理位置,以便在保留统计特征的同时避免映射到真实个体。 在合成大量数据用于自动化测试时,最好建立一套去重与碰撞检测机制,避免生成与现有真实用户重名的高风险情况。
可以跨参考公开的高频姓名与常用公众人物名单,排除明显可能与真实知名人物冲突的组合。 性能考虑与索引优化 当姓名数据规模达到百万级别时,检索、模糊匹配与相似度搜索可能成为性能瓶颈。采用合适的索引方式与分片策略是关键。一种常见做法是为姓、名以及组合字段分别建立b-tree或全文索引,并为模糊匹配使用trigram、Levenshtein或其他近似字符串搜索引擎。对于需要高吞吐量的应用,使用专门的搜索系统或内存索引来加速查询会更合适。 维护数据质量的流程 高质量姓名数据库需要持续的质量控制。
定期运行清洗规则来统一格式,记录解析错误与异常样本以驱动规则改进,定期更新核心频率数据以反映最新的命名趋势。建立采集来源记录与许可元数据,确保在数据生命周期内可以追溯来源与许可状态。在团队协作中,制定数据使用手册并进行合规培训,有助于减少误用风险。 常见应用场景与实践案例 姓名数据库的应用广泛,涵盖用户界面填充、合成测试数据、反欺诈规则的姓名验证、人口学研究、市场细分分析以及机器学习训练数据。举例来说,开发一款面向美国市场的电子表单产品,采用社会安全局的名字频率数据和人口普查的姓氏分布,可以在测试时生成贴近真实的用户样本,从而更好地评估UI在真实数据下的表现。在训练自然语言处理模型时,通过将按年份加权的名字列表与地区姓氏分布结合,可以提高模型对姓名实体的识别和消歧能力。
总结与实践建议 构建或使用英文名字与姓氏数据库并非单纯收集字符串,而是一个涵盖数据源甄别、格式设计、解析规则、隐私合规与性能优化的系统工程。优先选择权威与许可明确的公开数据源,如社会安全局和人口普查局,结合社区开源汇总与云端公共数据,能够快速构建可靠的数据基础。对名字进行规范化和解析时应保留原始字段,采用多策略来处理文化差异与异常情况。合成姓名数据是规避隐私风险的重要手段,但要尽量模拟真实分布并设置去重与冲突检测。最后,建立持续的质量控制与合规审查流程,确保数据在生命周期内保持可靠与合法。 掌握上述方法后,无论是为产品生成测试样本,还是为研究准备数据集,都可以在确保合规与伦理的同时提高工作效率。
探索不同数据源、结合地域与时间维度的权重,以及建立健全的清洗与解析流程,将帮助你打造既实用又安全的英文姓名数据库。 。