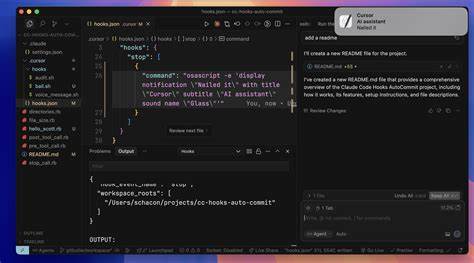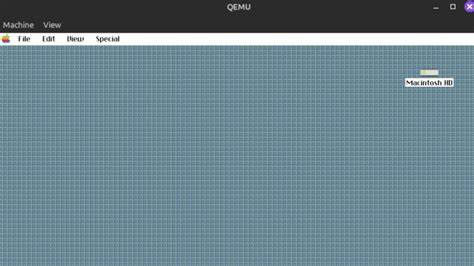
上世纪八九十年代的 Macintosh System 7 是个人计算史上的重要里程碑,其图形界面、工具箱 API 和应用生态对后来的操作系统设计产生深远影响。最近一项由独立开发者推动的工程引发了社区广泛关注:在没有官方源代码公开、主要基于原始二进制的条件下,借助反向工程工具和大语言模型(LLM),将 System 7 重新实现为能在 x86 平台上运行的可引导系统,并在 QEMU 中展示了 Finder 与 GUI 的基本功能。这个项目既是技术能力的展示,也引发了关于版权、方法学与可信性的热烈讨论。本文从技术细节、工作流、法律伦理、社区争议与未来影响等多个角度,对该事件做全面解析,并给出实践建议与可复用的思路。 对 System 7 移植工作的技术拆解 要把一个原本为 Motorola 68k 架构编写并深度耦合硬件(显示、内存管理、中断等)的操作系统改造到 x86 上,技术上涉及多个难点:指令集差异、字节序与对齐、系统调用与接口保持、设备驱动与硬件抽象、内存分配与堆管理等。项目作者采用的常见策略包括把原有二进制视为规范来源,通过反汇编和逆向分析复原逻辑,然后在目标平台上重实现相同的行为接口。
关键环节如下: 反向工程与二进制分析 利用 Ghidra 等静态分析工具对 68k 二进制进行反汇编和流图提取是第一步。反汇编输出、函数边界识别、字符串表与数据结构复建都需要人类工程师的判断。LLM 在这里的作用通常是作为增强型助手:根据函数汇编片段、字符串和上下文推测函数的功能、生成注释、帮助命名变量与恢复数据结构。相比纯人工分析,LLM 可以快速给出合理的函数签名和伪代码建议,加速探索与验证环节。 从汇编到可读源代码的迁移 将汇编语义转译为更高层语言(如 C)是一种常见做法。方法可以是手工重写,也可以利用工具把反汇编或中间表示转换为 C 伪代码,再由开发者整理。
LLM 可以在这一阶段提供模板化的重构建议,例如如何把寄存器参数转换为函数参数,如何实现原始内存布局映射为结构体。关键是保持行为等价,而不是逐句复制原始实施细节,以避免直接复制可能受版权保护的实现。 抽象层与设备模拟 一个操作系统对硬件的依赖极强。项目作者选择在 QEMU 中运行重实现的 System 7,利用 QEMU 提供的通用设备和 BIOS 接口来屏蔽具体 PC 芯片组差异。通过在系统中实现一组兼容 System 7 Toolbox 的 API(例如图形绘制、窗口管理、事件循环等),上层应用和 Finder 可以在不知情的情况下运行在新的硬件抽象层上。简而言之,重实现的目的是提供与原始 OS 相同的接口,而不是复制原始的内部实现。
测试与迭代 在虚拟机中进行快速迭代是常见的工程实践。QEMU 提供的可控硬件环境、串口日志、内存快照与调试接口使得反向工程回路缩短。LLM 可以辅助生成测试用例、解析日志和建议调试步骤,从而在短时间内修复大量不一致之处。作者报告称在短短数天内搭建出一个"可引导骨架"并让 Finder 基本工作,显示了现代工具链与自动化辅助的效率提升。 大语言模型在工程流程中的角色与限制 在该项目的叙述中,LLM 被视为显著加速器。具体作用包括注释生成、伪代码化、函数命名建议、自动化补全与单元测试草案生成。
对许多重复性高或需要大量模式识别的任务,LLM 可以带来显著生产力提升。然而,需要注意其固有限制:LLM 有"幻觉"(hallucination)风险,会在缺乏明确证据时生成不准确或错误的实现建议;它也可能在训练数据中吸收受版权保护的片段,从而在生成代码时复现受保护内容。 围绕"clean room"与原始代码来源的争议 此类工程最大争议之一是实现过程是否涉及未经授权的原始源代码复用。社区中出现的质疑集中在:项目仓库内是否存在直接来自 Apple 内部或泄露源码的片段,或者作者是否在开发过程中把这些源码输入到 LLM 以生成重实现。项目作者回应已采用函数级差异检测、代码克隆检测工具,并提供了一份衍生性说明与可复现构建脚本,用以证明其实现是通过二进制分析和重写完成的。然而,评论区中也有人指出历史性的"SuperMario" ROM 源码仓库的存在以及仓库某些早期提交中对 Apple 内部符号的引用,使得溯源问题复杂化。
法律与伦理考量 将封闭代码或二进制重实现为可运行系统涉及多个法律层面。版权问题是最核心的:直接复制受版权保护的代码或以太接近复制的实现方法都可能构成侵权。所谓"clean room"再实现通常要求开发团队在无接触受保护源代码的情况下,仅基于公开规格或干净的接口定义完成实现,并保留过程记录以便辩护。若使用 LLM 并把受版权保护的代码作为"提示"或训练素材,产生的输出可能被认为含有被训练材料的痕迹,从而触及法律风险。除此之外,某些平台的 EULA、SDK 协议也可能对逆向工程与再分发做出限制。 实践建议与风险缓解 在尝试类似工程之前,建议采取若干风险缓解措施。
首要是明确目的:如果目标是实现数字考古、数据迁移或教育研究,应当把这些目的记录化,并尽可能采用公开文件、规格手册与干净的二进制分析流程。尽量避免直接输入疑似受保护的源代码到任何外部 LLM 服务;若需使用 LLM,优先采用本地部署或受控环境以保护过程可审计性。保留完整的工作流日志、版本控制历史与差异检测报告对于应对后续法律质疑非常重要。 如何在 QEMU 中运行与贡献 对于希望体验或参与该项目的开发者,一般流程包括从项目 GitHub 克隆仓库、安装所需工具链与依赖、构建镜像并在 QEMU 中引导。常见构建依赖可能包括多架构工具链、mtools、gcc-multilib 等包。作者通常会在仓库内提供构建脚本与可复现环境说明,社区贡献者可在遵守许可证与贡献指南的前提下提出补丁或改进。
务必在参与前阅读仓库的 LICENSE、CONTRIBUTING 与 DERIVATION 或 ARCHAEOLOGY 文档,以了解作者声称的开发方法与合规说明。 为何这件事对数字保存与软件考古重要 老软件的保存并非简单地保存磁盘镜像或二进制文件。要让历史数据可访问、可迁移并为后世理解,往往需要能在现代平台上运行历史环境,或者构建兼容层以导出数据为现代格式。将 System 7 这种历史操作系统移植到可在虚拟化环境中运行的实现,能为保存旧格式的文档、图像以及科研数据提供可行路径。对于研究者、博物馆与长期存储者来说,这类工程有重要价值。 对开发者与社区的现实建议 对于怀有类似想法的开发者,建议从几方面着手:优先明确法律边界与项目目标,采用可审计的工作流程,使用公开文档与历史资料做为参考;把 LLM 当成增强工具而非"魔法替身",严密验证每一个模型建议;积极与法律顾问或版权专家沟通,必要时寻求许可或与权利方协商。
对于社区管理者和开源托管平台,建议制定清晰的合规与取证指南,尤其在涉及可能受版权保护的反向工程内容时提供明确流程。 对未来的展望:LLM、反向工程与软件保存的融合 该事件展示了一个更广泛的趋势:大语言模型和自动化分析工具正在改变软件逆向工程与再实现的可能性。随着模型能力提升,更多繁重的分析工作可以被自动化,工程周期被大幅缩短。然而与此同时,法律、伦理与可信性问题也将成为必须严肃对待的议题。未来的可取路径是建立标准化的"数字考古"流程,结合可复现的技术手段、审计机制与伦理约束,把技术能力用在合法且有社会价值的方向上。 结语 将 Macintosh System 7 移植到 x86 并在 QEMU 上运行的工程是技术能力与工程流程结合的一个有趣案例。
它展示了现代工具链与 LLM 在加速复杂逆向工程任务中的潜力,也提醒我们在追求技术突破的同时必须正视版权与方法论的边界。对任何希望在软件保存、历史重建或兼容层实现方面投入精力的人而言,既要善用新工具提高效率,也要谨慎处理法律与伦理风险,以确保研究与实践能够为更广泛的技术遗产保护作出长期贡献。 。