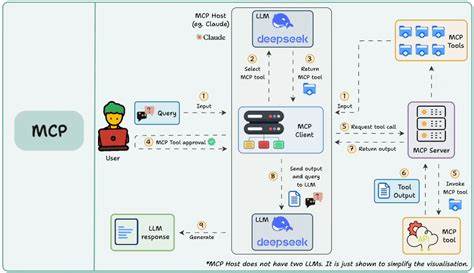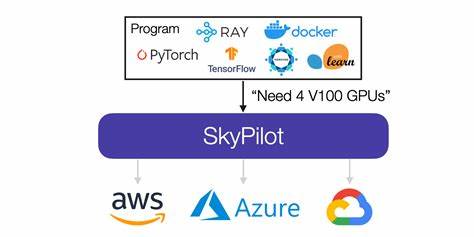
在当今人工智能飞速发展的浪潮中,尤其是大型语言模型(LLM)和复杂分布式机器学习工作负载的兴起,计算资源的性能瓶颈已逐渐转向网络性能。尤其是在多节点GPU集群的训练过程中,网络传输的效率直接决定了整体任务的执行速度和成本效益。高延迟或带宽不足的网络设置不仅影响模型训练速度,更可能让昂贵的GPU集群因无法发挥性能而沦为“高价暖气片”。然而,面对多家云服务商不同的网络架构及管理系统,如何统一且高效地配置GPU网络,成为了许多研发团队头疼的难题。SkyPilot正是在此痛点上应运而生,通过自动化和抽象化的网络层策略,极大地简化了跨云GPU网络的复杂配置,助力用户专注于核心算法与模型创新。SkyPilot深入理解当前主流云平台——诸如谷歌云(GCP)、Nebius以及Kubernetes托管服务(如GKE、EKS)等提供的不同网络架构特点,各平台在实现高性能GPU通信方面使用了不同的技术栈。
以GCP为例,针对不同型号的GPU实例采用了诸如GPUDirect-TCPX、GPUDirect-TCPXO以及GPUDirect-RDMA等先进技术,充分发挥NVIDIA H100、B200等GPU的传输优势。而Nebius则倾向于使用带有MLX5适配器和UCX优化的InfiniBand方案为用户带来低延迟高带宽的网络体验。当这些初看似相似的环境,叠加上托管Kubernetes服务引入的额外网络层、容器编排复杂度和GPU设备插件配置,整个网络环境的设置变得极其复杂。一旦用户手动配置网络,往往需要参考冗长的云厂商手册,针对特定机型逐步完成复杂的网络与驱动安装、环境变量配置的流程。任何一步配置失误,都可能导致长时间的调试,损失不可估量的算力和时间。网友们就曾形象地比喻,试错三天的代价就可高达数千美元,尤其是当涉及到昂贵的新一代GPU如H200x8群集时,这种损失不可忽视。
此外,手工流程缺乏统一标准,每次迁移到新云供应商或新实例类型,都意味着重新摸索和配置。托管Kubernetes环境更引入了Pod网络设置和GPU设备插件的额外挑战,加剧了网络管理的复杂度。在此背景下,SkyPilot提出了革命性的“网络层抽象”(network tier abstraction)方案。用户仅需在配置文件里加入一行“network_tier: best”,系统便自动识别底层云平台与实例类型,智能配置最优网络栈,彻底摆脱人工烦琐操作。这个简简单单的配置,将复杂数十条命令合并为自动执行的脚本,确保网络的稳定与高性能。SkyPilot不仅支撑传统云虚拟机,还兼容托管Kubernetes环境,打破了此前两类架构网络管理的壁垒,为多云多集群环境的深度集成铺平道路。
性能验证方面,SkyPilot在GCP环境下对配置了两台a3-highgpu-8g实例的集群进行了NCCL性能测试,证明在大规模通信中,GPUDirect-TCPX网络配置较标准网络最高可达3.8倍的通信加速。除此之外,针对LLM推理工作负载的实际需求,优化的网络配置带来了11.3%的吞吐量提升和8%的延迟降低,显著优化服务响应速度与系统资源利用率。在日趋激烈的AI算力市场中,这样的网络优化不仅节约成本,更提升了研发团队的整体竞争力。正如SkyPilot团队在其官方博客中所言,他们持续扩展网络层抽象的覆盖面,计划支持包括AWS Elastic Fabric Adapter(EFA)、Azure InfiniBand、Oracle云的RoCE技术、Lambda Labs以及CoreWeave等多种网络方案,进一步实现跨云多平台的无缝GPU网络自动化。未来,SkyPilot还致力于结合最新的云基础设施创新,不断丰富其网络抽象层功能,力求成为分布式AI训练和推理的首选基础设施平台。总的来说,SkyPilot用自动化编排替代手工配置,以强大且统一的网络抽象,解决了GPU多云部署中网络配置的难题。
用户无需再为每个云平台、实例类型或Kubernetes环境勾勒复杂的网络拓扑和参数,极大降低了技术门槛并节省了宝贵时间。驱动用户聚焦于模型研发和业务创新,SkyPilot无疑成为了通往未来智能计算时代的关键桥梁。对于需要跨云部署大规模GPU集群的AI团队而言,借助SkyPilot强大的网络自动化方案,将显著提升训练和推理的效率与成本效益。随着AI应用的不断深入与复杂化,高效且智能的底层基础设施服务成为不可或缺的支持力量。SkyPilot正以其卓越的网络配置能力,助推AI算力生态朝着更智能化、多样化的方向快速演进。