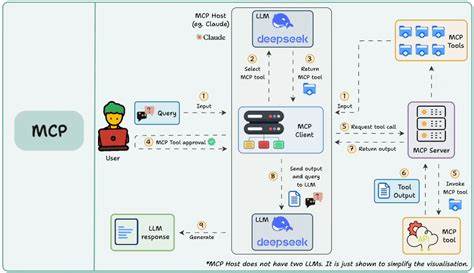
随着人工智能技术的飞速发展,自然语言处理模型(LLM)在诸多场景中表现卓越,成为对话系统、内容生成及任务执行的重要基础。然而,语言模型本身对视觉信息的理解和处理能力有限,这在某些应用场景中形成瓶颈。如何让基于语言模型的MCP智能体拥有强大的视觉处理能力,成为当前AI领域亟待攻克的难题。VLM Run MCP服务器的推出,提供了完美的解决方案。通过多模态工具调用技术,VLM Run MCP实现了对视觉内容的深度理解和自动化处理,极大增强了MCP智能体的综合能力。 多模态工具调用,顾名思义,是指智能体能够在任务执行中调用不同类型的工具,包含视觉解析、文档处理、视频分析等多种能力,实现信息的多维度融合与交互。
传统单一模式的智能体只能处理文本输入,而视觉信息如图片、PDF文档、视频等则需要额外复杂的接口和集成,增加开发难度和系统复杂性。VLM Run MCP改变了这一现状,它通过符合Model Context Protocol(MCP)标准的服务器架构,作为语言模型与视觉处理工具之间的桥梁,实现了工具自动发现和调用,使得多模态处理流程达到高度自动化和无缝衔接。 VLM Run MCP服务器提供了丰富的视觉AI工具集,涵盖图像分类、文本提取、人脸检测与模糊处理、复杂文档数据解析以至视频转录和场景搜索等多样功能。这些工具模块经过精心设计,既支持独立调用,也能协同工作,以满足不同业务场景的复杂需求。通过接入VLM Run MCP,AI智能体无需开发者手动集成具体算法和接口,只需在自然语言对话中发起请求,系统即可自动选择并调用合适的视觉工具,实现任务的端到端闭环处理。例如,当智能体接收到带有发票图片的请求时,能够自动调用发票数据抽取工具,精准识别并返回结构化账单信息,无需人工介入。
VLM Run MCP的工作流程极为高效。首先,开发者在智能体的MCP客户端配置中添加VLM Run MCP服务器地址及认证信息,接着智能体自动发现服务器上的所有可用视觉工具。此后,用户在自然语言交互中提出视觉处理需求,智能体根据上下文智能匹配调用工具,后台完成图像上传、分析、数据提取等操作。最终,智能体将结构化结果返回给用户或执行后续动作。整个过程透明流畅,极大提升了用户体验和系统响应速度。当前VLM Run提供的核心工具如图像解析(parse_image)、文档解析(parse_document)、文件上传(put_file_url)等,已覆盖绝大多数常见视觉任务,可广泛应用于财务审核、法律合同梳理、会议视频分析、隐私保护等多个领域。
此外,团队持续优化和扩展工具库,适应更多行业需求。 VLM Run MCP服务器的价值不仅在于技术实现,更在于降低了视觉AI技术的门槛。过去构建具备视觉理解能力的智能体,往往需要投入大量研发资源,集成各类深度学习模型,面对接口兼容和性能调优等挑战。通过VLM Run MCP,开发者只需关注业务逻辑和高层流程,视觉处理完全交由服务器管理,极大缩短开发周期,节省成本。同时,因服务器托管于云端,还能保证工具的及时更新与扩展,使智能体始终掌握前沿视觉技术。 展望未来,多模态智能体必将成为人工智能发展的主流,融合语言、视觉、听觉等多方面感知,让人机交互更自然、更高效。
VLM Run MCP作为多模态工具调用的典范,为行业提供了成熟且易用的解决方案。无论是希望提升现有语言模型的视觉能力,还是构建新一代多模态智能体,VLM Run MCP都展现出强大的技术优势和灵活应用潜力。 目前,用户可通过VLM Run平台注册获取API密钥,简单配置后便能接入其MCP服务器。官方提供的快速上手教程和示例项目进一步降低了入门门槛,使广大开发者、企业和研究者快速打造定制化视觉智能解决方案。 凭借多模态工具调用的创新思路和稳定可靠的服务器平台,VLM Run MCP成功解决了长期困扰多模态智能体的工具调用难题,推动了视觉AI技术在智能代理领域的广泛应用。未来,随着新工具和功能的不断加入,VLM Run MCP必将持续引领智能体视觉能力的技术发展,助力各行业智能化转型升级。
。