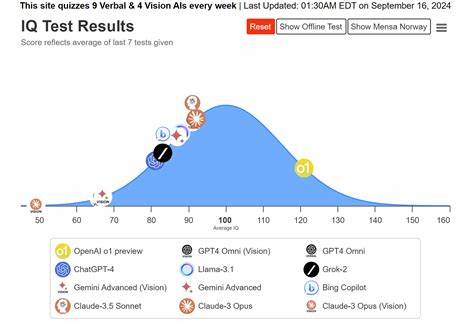
随着人工智能技术的飞速发展,如何准确评估和监控AI系统的智能水平成为业内关注的焦点之一。智力测评,尤其是基于IQ测试的方法,逐渐成为衡量AI性能的有效工具。通过系统化、标准化的测试方式,不仅可以了解现有AI在解决问题、理解语言和图像识别等方面的能力,还能为其未来的优化和升级提供科学依据。最近,TrackingAI.org作为“Maximum Truth”项目的一部分,便致力于对多种领先的AI模型进行周期性的IQ测试。该平台每周对15款语言AI与9款视觉AI进行测验,实时更新成绩,形成丰富的数据资源,促进了业界对AI智能水平的透明化监控。AI IQ测试涵盖多个维度,特别注重语言理解和视觉识别两大核心能力。
测试结果以得分形式呈现,覆盖区间从55到145不等,反映了不同AI模型的综合智能实力。诸如Claude-4 Opus、OpenAI的o3 Pro和o4系列、Gemini 2.5 Pro、Llama 4 Maverick等主流AI,在多个版本中展现出差异化表现,体现了技术迭代带来的性能提升和能力深化。这些测评数据不仅帮助用户直观比较不同AI的性能,还能为开发者提供优化方向。例如,一些AI在语言类测试中表现卓越,但视觉测试得分相对较低,揭示了其多模态理解能力的潜力和限制。此外,根据系统的历史数据分析,AI的IQ成绩随着时间推移呈现出稳步提升趋势。通过连续的测试和跟踪,可以发现新模型往往在能力上实现质的飞跃,体现了训练数据质的改进和算法框架的创新。
如此动态的IQ监测,对于评估AI适应现实复杂环境的敏捷性和稳定性,具有重要指导意义。除技术层面外,TrackingAI平台还提供丰富的交互功能。用户可以浏览每款AI的详细回答记录,深入理解其知识结构和推理过程,这为研究语言模型在不同题型下的表现提供生动案例。另外,平台还配备了搜索数据库,方便用户精准查找相关模型和测试结果,提升使用体验。值得关注的是,AI的IQ表现并非绝对衡量智能的唯一标准。测试环境虽然力求贴近实际,但依然有局限性。
比如,测试素材和题型的选择,可能带有一定的偏向性或适应性差异。因此,研究人员和开发者需将智力测评结果与实际应用中AI的表现结合起来,综合评价其整体价值。此外,当前AI模型在不同文化背景与语言环境下的适应性也存在挑战。IQ测试结果反映的是模型在特定测试体系下的能力,而非涵盖所有实际应用场景的万能指标。未来,跨语言多元文化的测试体系建设,将是推动AI智能估测更科学全面的关键。在技术创新不断推进的时代,监测人工智能智商测试不仅为AI行业的健康发展提供理论基础和实践支持,同时也助力广大用户更理性地理解AI能力与局限。
通过透明且持续的测评机制,促进AI企业在产品研发和伦理规范方面的标准化,有助于建设可信赖的智能生态环境。总结来看,人工智能IQ测试作为测量和监控AI智能水平的重要工具,正在成为AI技术发展的风向标。多款领先AI模型在语言和视觉任务中的表现展示了科技的进步,也映射出未来研究的方向。借助持续、科学的监测体系,各界能够更加精准把握AI发展的脉络,为人类社会与智能机器的协同共生奠定坚实基础。