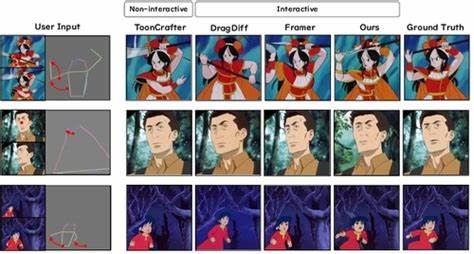
大型语言模型(Large Language Models,简称LLM)近年来成为人工智能领域的焦点,特别是在ChatGPT等产品的带动下,这种技术迅速渗透到搜索引擎、代码辅助、文档编辑甚至社交聊天工具当中。然而,随着应用场景的快速扩展,关于大型语言模型的误解和神话也层出不穷,很多用户并不了解其底层机理,反而对它们的能力抱有过高或错误的期待。本文将深入探讨五个关于大型语言模型的常见误区,揭示它们的真相,帮助大家建立科学认知。首先,很多人认为大型语言模型能够真正“对话”并理解交互内容。表面上看,聊天机器人可以像人类一样轮流回应,并且对对话的上下文进行连贯记忆,但事实是,LLM其实并不具备真实的“对话”能力。它们的核心功能是预测给定文本后最有可能出现的下一个词,基于大量训练数据统计出最有可能的文本延续。
在与用户的对话中,模型通过输入已经发生的对话文字作为上下文,然后生成极有可能作为下一句出现的回复,这种机制并不区分“用户”还是“机器人”,对话本身只是语言连续性的体现,而非真正的交流或心理活动。因此,所谓的“聊天能力”更多是表象,背后本质是概率上的文本生成。其次,很多人误以为大型语言模型接收的是文本字符串,直接处理我们输入的字符。实际上,模型根本看不到字符,而是基于“分词”(tokenization)过程将文本拆分成“词元”,这些词元可能是一个完整的词,也可能是词的一部分,甚至是特殊符号。每个词元会被转换为一个高维的向量,也就是数学上的“嵌入向量(embedding)”,它包含了该词元与其他词元之间的语义关系。通过这种向量化的方式,模型能够捕捉词与词之间的内在联系和语义相似度,这是理解和预测文本的基础。
这种向量在几百到几千维度的空间中表示词元,维度越高,模型捕捉的语言细节越丰富。再来看输出部分,最大的误解之一是认为大型语言模型直接“产生文本”。而实际上,模型每步给出的并不是文本本身,而是对所有可能的下一个词元的概率分布。模型会为词库中成千上万个词元分别估算概率,然后根据一定的策略(称为“解码”方法)选出一个结果。常见的解码策略会通过设置“温度”等参数控制随机程度,低温度时倾向输出最有可能的词元,高温度时则更易出现多样化和创新的表达。输出的文本正是基于这种逐步选词,反复反馈进模型输入形成的“自回归生成”过程,直到模型选择停止符或者达到最大长度限制。
大量文本生成的背后正是这样一系列不断迭代预测的结果。关于模型训练目标,公众普遍怀疑大型语言模型是否经过复杂多样的专业训练。实际上,绝大多数LLM的核心训练目标其实非常简单:预测下一词元是什么。通过大量互联网上采集的文本,模型不断练习“填空”游戏,尝试预测下一词元,并根据预测与真实结果的误差调整其内部参数。采用的数学方法包括交叉熵损失和反向传播算法,帮助模型慢慢学会语言的规则和表达的概率分布。虽然后续辅助训练阶段,如监督微调和人类反馈强化学习,会带来调整和性能改进,但根基依然是“猜下一个词”的目标。
最后,很多人误以为大型语言模型能够像人类那样“记住”对话内容或训练后产生的知识,从而持续学习和更新。事实上,LLM的记忆是有限且被动的。它们的模型权重在训练结束后就被固定,不具备在线更新或积累新的知识的能力。所谓的“上下文记忆”其实是通过将之前的对话历史作为输入的一部分传入模型实现的,模型本身不存储历史。再加上模型只有固定大小的上下文窗口,超出部分会被截断,导致长对话中早先信息遗失或影响生成质量。尽管有些应用加入了记忆管理层,通过数据库或辅助模块保存用户信息来模拟“记忆”,但本质上这些均属于附加的技术手段,非语言模型本身的能力。
随着新技术不断涌现,模型的持续学习和记忆能力可能会有所突破,但目前依然是“冻结”的状态。综合来看,大型语言模型是统计驱动的文本生成机器,通过将输入转化为词元向量,预测词元概率,以自回归方式生成输出。它们不具备真正的思考、理解、记忆或推理能力,也无所谓专门的领域训练,而是依赖海量数据中语言模式的统计特征。这样的认识帮助我们正确看待其优势与限制,更理性地利用这项技术。对开发者而言,清晰理解LLM的工作原理有助于设计更有效的应用和交互策略,避免因过高期待而产生误用。对于普通用户,也应了解聊天机器人的“会说话”本质是概率预测而非智能对话,把它当成方便的语言工具而非真正的智能体。
未来,人工智能领域将继续探索融合知识、记忆和推理的新方法,推动大型语言模型向更强的认知能力发展。但在此之前,认识和破解这些误区,是我们走向更稳健应用和创新的坚实基础。随着技术深入人们生活,对大型语言模型本质的科普和理解显得尤为重要。