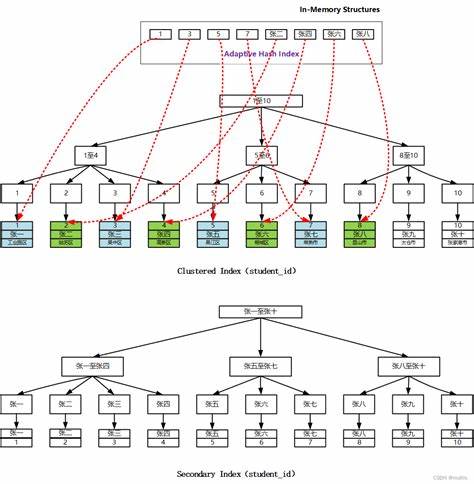
哈希表作为计算机科学和软件工程中极其重要的数据结构之一,因其平均情况下常数时间的查找、插入和删除效率,被广泛应用于数据库管理、缓存系统、编译器设计等诸多领域。然而,传统哈希表在面对复杂多变的键分布及极端场景时,往往会出现性能瓶颈,特别是当碰撞增多导致链表过长或重哈希频繁时,会严重影响整体效率。近年来,自适应哈希技术正逐渐成为解决这一问题的有力武器。通过动态调整哈希函数,自适应哈希不仅能够提升查找和插入的速度,还能增强哈希表的鲁棒性,适应不同数据分布的实际需求,开创了哈希表性能优化的新局面。哈希表的核心在于将任意复杂的键映射到一个固定大小的桶数组索引,从而实现高效的访问。传统哈希算法设计通常考虑最坏情况的时间复杂度,以保证性能的下界,但实际使用中,忽略了影响效率的常数因素——这些因素在实际运行时往往更为关键。
而且,传统设计多选择固定哈希函数,这就限制了哈希表对实际键分布的适应能力,往往导致大量碰撞和非最优的缓存性能。自适应哈希的理念始于对完美哈希技术的启发,后者强调为给定的键集合选择最优哈希函数,以实现零碰撞。然而,完美哈希针对的是固定、静态的键集合,缺乏动态扩展性,难以满足大多数通用哈希表的需要。而自适应哈希突破了这一限制,允许哈希函数在哈希表生命周期内根据键的实际分布动态调整,实现在线优化。自适应哈希的最大优势在于有效减少碰撞数,提高哈希表访问效率。例如,SBCL(Steel Bank Common Lisp)实现中的自适应哈希表,初始状态采用常数哈希函数,实际表现为空间内线性搜索;当键数超过阈值且需重新哈希时,系统会检测键的低位比特共同特征,利用单次右移操作构造简单高效的哈希函数,这一方法对内存分配器行为极为友好,尤其适用于顺序分配的多重对象。
若仍存在太多碰撞,自适应机制会升级为SBCL默认的快速EQ散列函数,再不行则切换到通用Robust哈希函数如Murmur,甚至可以选择更强力的加密哈希以保保障极端情况。这种分层切换策略使得自适应哈希表既保证了普通情况下的高速访问,也能在恶劣负载下保持稳定,减少了哈希退化带来的性能惩罚。对于EQUAL类型的复合键,哈希计算开销通常较大,自适应哈希技术同样提供了优化方案。通过只对字符串键的首尾少数字符进行哈希计算,或者只针对列表键的前几元素进行处理,极大减少了哈希函数计算负担,同时在碰撞过多时动态调整计算范围,实现平衡性能与准确性的动态适应。自适应哈希技术不仅是对传统哈希理论的创新应用,更体现了理论与实际工程需求结合的重要趋势。理论上,哈希算法强调随机选择函数以保证均匀分布,而工程实践中,哈希函数固定且数据分布往往存在规律,密切观察和利用这种规律成为提升性能的关键。
通过监控碰撞链长度、碰撞次数及哈希表大小,自适应哈希机制能够在运行时识别性能瓶颈,调整策略以保障整体效率最大化。随着数据规模和访问模式的复杂化,保障哈希表性能的鲁棒性显得尤为重要。自适应哈希为现代语言运行时系统和基础软件库提供了可靠的性能保障手段。SBCL项目的成功实践展示了将自适应哈希融入真实世界大型系统的潜力,同时也为其他编程语言和平台提供了参考样本。未来,自适应哈希有望结合机器学习等智能化技术,进一步提升其对复杂数据分布的自我调节能力,实现更智能化的动态优化。同时,随着硬件架构的发展,尤其是多核和缓存体系不断演进,自适应哈希如何更好地利用硬件特性,实现缓存友好设计和减少内存访问延迟,也将成为研究热点。
总之,自适应哈希技术不仅为哈希表性能优化提供了新思路,也为更广泛的数据结构设计和应用场景带来了启示。通过动态适应实际数据分布和访问模式,它实现了速度与鲁棒性的完美平衡,是现代计算系统不可忽视的关键技术方向。对于开发者而言,深入理解和掌握自适应哈希的原理及实现,有助于打造更高效、更稳定的软件系统,推动软件性能优化迈上新台阶。随着相关技术不断成熟和应用领域不断拓宽,自适应哈希注定成为未来数据结构优化中的重要里程碑,为软件工程领域带来深远影响。