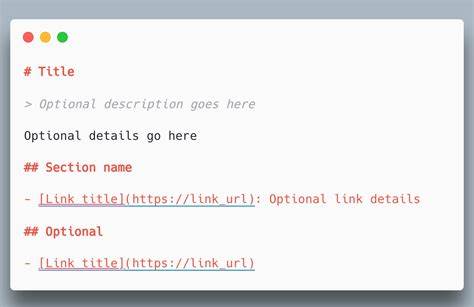
随着大型语言模型(LLMs)在人工智能领域的广泛应用,如何高效且合规地爬取并利用网站内容成为业界重点关注的话题。LLMs.txt,这一由澳大利亚技术专家Jeremy Howard提出的新标准,借鉴并延伸了robots.txt及XML网站地图的理念,针对AI模型对于网页内容的特殊需求,提出了一种简洁且技术友好的文本文件方案。该方案不仅能够改善大型语言模型爬取网页内容时的资源消耗问题,还能够为内容拥有者提供更灵活的内容管理工具,保障内容版权和品牌形象。LLMs.txt文件主要是以Markdown格式编写的纯文本文件,放置在网站根目录下,旨在为AI模型提供经过扁平化处理的网页内容,剔除复杂的HTML标签、导航结构、广告及JavaScript代码等冗余信息,使得模型能快速准确地读取核心内容。与传统的robots.txt不同,LLMs.txt并非用于阻止爬虫访问,而是通过明确指定哪些内容适合AI模型访问及如何访问,达到内容选择性开放的目的。网站管理员可以根据需求,将网站的部分栏目链接、摘要或者完整文本以文档形式供AI读取,甚至可以将整站内容整合成一个大型的llms-full.txt文件,从而最大化信息的利用效率。
这种“全网扁平化”内容呈现方式,不仅便于大规模文本分析,也为AI开发者提供了标准化的内容源,减少了对复杂网页结构解析的依赖。LLMs.txt的价值远超技术层面,它预示着网站内容治理进入了新阶段。在当前数字生态中,内容版权保护和品牌信息安全成为企业关注重点,如何平衡开放数据与保护权益,是亟需解决的难题。通过LLMs.txt,企业可以在不完全封禁内容的前提下,选择性地向AI提供能够代表品牌形象和核心价值的信息,减少因训练数据滥用带来的风险。此外,扁平化的文本内容还可用于内部SEO分析、关键词研究、网站架构优化及竞争对手调研等多种应用场景,赋能数字营销和内容策略的科学决策。当前,虽然LLMs.txt还处于推广初期,但已有众多主流AI开发者与内容平台表示关注并逐步应用。
诸如Anthropic、Hugging Face、Perplexity等领军企业均已发布或正在测试LLMs.txt文件,标志着该标准正在稳步走向行业认可。与此同时,市场上也涌现出多款LLMs.txt生成工具,包括开源的Markdowner及专门为WordPress开发的插件等,帮助网站运营者快速创建并管理自己的LLMs.txt文件。然而,LLMs.txt的推广和普及并非一帆风顺。其面临的挑战主要包括业界对标准接受度的不确定性、不同AI平台对文件遵守性的差异、以及潜在的信息安全和内容泄露风险。部分SEO和数字营销专家持怀疑态度,他们认为LLMs.txt与现有robots.txt和XML网站地图存在功能重叠,效果提升有限,同时也警惕滥用该文件进行关键词堆砌或内容刷新的可能。知名业界人士例如Pubcon及WebmasterWorld的领导者便提出,未来搜索引擎和大型语言模型将融合为一体,区分两者的界限日益模糊,LLMs.txt的存在价值值得商榷。
尽管如此,支持者认为LLMs.txt是迈向科学化、规范化AI内容治理的第一步。相比于传统的内容管理方式,它以更为精准、透明的手段,为网站内容开放与保护提供了桥梁。对于希望在未来AI驱动的内容分发中占据优势的品牌和网站而言,尽早布局和实施LLMs.txt无疑十分具有战略意义。SEO与数字营销领域尤其需要关注这一标准的动态,及时调整内容架构与策略,确保在AI辅助的搜索环境中保持竞争力。未来,LLMs.txt不仅可能成为标准化的内容爬取协议,还将推动一系列相关技术的发展,如内容验证、数据溯源及AI训练数据许可管理等,为构建健康、公平的数字内容生态贡献力量。总体来看,LLMs.txt代表了AI与网站内容互动的崭新范式,在人工智能持续渗透各行各业的当下,理解并积极应用这一标准,将助力企业有效管理网站内容,提升AI交互效果,同时保护自身知识产权和品牌信誉。
随着业界不断完善协议细节及推动标准化进程,LLMs.txt未来的影响力和普及度有望持续扩大,成为数字时代内容治理和AI爬取的基石之一。