随着现代软件开发对性能与跨平台能力的需求日益增长,编译技术也在不断演进以适应多样化的应用场景。GraalVM作为一个多语言运行时环境,致力于提升Java及其他语言的执行效率和互操作能力,而其LLVM后端的出现,则为Java程序的原生化执行开辟了全新路径。本文将深度解析GraalVM的LLVM后端,带您了解其技术细节、实际应用及未来展望。 GraalVM的设计理念基于编译器技术的现代进展,它核心依赖Graal编译器将Java字节码转化为机器码,从而实现高效的即时编译(JIT)。此外,GraalVM提供了native-image工具,以提前编译(AOT)的方式将Java程序打包为原生二进制文件,这不仅缩短启动时间,也提升了程序运行性能。传统上,native-image默认使用Graal自身的后端技术完成二进制生成,而LLVM后端作为一个实验性模块,则尝试通过LLVM框架来完成这一过程。
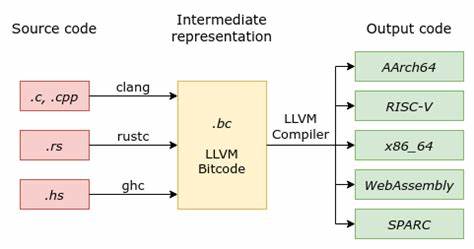
LLVM是目前广泛应用的编译基础设施,其引入了中间表示(IR)的概念,使得不同语言和平台可以在统一的中间层进行优化和代码生成。LLVM支持众多前端语言,如Rust、Swift和Haskell,而其后端进一步负责将IR转化为具体平台的机器码。GraalVM在此基础上不仅实现了将Java字节码编译成Graal IR,还通过名为Sulong的前端支持LLVM位码的执行,从而实现了多语言间的紧密联动。 LLVM后端的引入使得native-image能够生成高度优化的LLVM位码,从而利用LLVM所支持的多种目标架构及优化策略。这一设计特别适合需要跨平台部署和极致性能的场景,比如嵌入式系统、云计算节点等。LLVM后端通过生成位码文件,随后借助LLVM工具链完成目标机器码构建,有效扩展了GraalVM的适用范围和灵活性。
实操方面,使用GraalVM LLVM后端进行原生编译十分便捷。用户首先需要确保本地安装有支持的GraalVM版本,同时安装native-image和llvm-toolchain组件。接着,编写Java程序并用GraalVM自带的javac进行字节码编译。随后,调用native-image时通过-H:CompilerBackend=llvm参数指明后端使用LLVM,结合必要的特性配置,即可生成LLVM位码并完成原生二进制构建。 生成的可执行文件体积一般会较传统native-image稍大,约在十几兆字节规模,因为包含了完整的运行时子系统和LLVM库支持。位码文件数量众多,涵盖了垃圾收集、线程管理等核心功能,这些构成了GraalVM子系统(SubstrateVM)的基础。
虽然目前LLVM后端仍处于实验阶段,文档和社区资源相对有限,但其开源特性使得开发者可以深入底层,积极参与创新和优化。 从技术视角看,GraalVM LLVM后端的优势包含在于丰富的LLVM生态和高度可扩展的目标平台支持。借助LLVM的成熟优化通路,GraalVM可以实现更细粒度的性能调优和硬件利用率提升。此外,LLVM后端为跨语言运行时互操作奠定基础,通过统一的位码格式降低多语言集成的复杂度,促进软件组件复用。 然而,LLVM后端也面临诸多挑战。首要是兼容性和稳定性尚未完全成熟,部分Java特性和语言动态性在LLVM框架内的表现需持续验证。
此外,整体工具链集成和调试支持还需进一步完善,帮助开发者更高效地定位和解决问题。未来,社区的持续贡献和官方支持将逐步推动LLVM后端走向生产就绪状态。 展望未来,GraalVM的LLVM后端有望成为连接Java与底层硬件间的桥梁,尤其是在物联网、机器学习推理及高性能计算等新兴领域发挥关键作用。借助LLVM工具链的开放性,开发者可以定制特定的优化策略,适配多样硬件架构,极大提升Java应用的适用范围和性能表现。同时,随着多语言协作需求增长,LLVM作为统一中间层的优势将进一步凸显,推动跨语言生态融合。 总结来看,GraalVM的LLVM后端利用LLVM框架的强大能力,丰富了Java应用的编译和执行手段,为原生编译带来革命性的可能。
尽管目前仍处于实验探索阶段,但其未来应用潜力巨大,值得广大开发者和研究人员关注与参与。掌握其原理和操作流程不仅有助于提升技术视野,更为开发高性能、跨平台的软件系统提供了创新途径。随着社区的壮大和技术的成熟,GraalVM LLVM后端注定将引领Java编译技术进入一个新的时代。 。