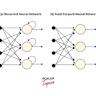
在现代人工智能尤其是深度学习领域,神经网络架构的设计至关重要。设计出一个最优的神经网络架构不仅能够提升模型的准确性和泛化能力,还能有效节省计算资源和训练时间。然而,目前在神经网络架构的选择上,仍存在许多不确定性和经验性成分,这让许多研究者和工程师困惑:是否存在一种确定的方法能够在训练之前预测某个架构的优劣,还是只能依靠反复试验与调参? 神经网络架构的复杂性源于其包含大量参数和不同的层次结构。常见的网络架构包括卷积神经网络(CNN)、循环神经网络(RNN)、变换器(Transformer)等,每种架构针对不同的任务和数据表现出独特的优势和限制。举例而言,Transformer架构的出现推动了大规模语言模型的革命,但其众多层叠结构和高维度参数也带来了设计上的挑战。 设计最优架构的传统途径主要依赖于经验和反复的试错过程。
研究人员会根据任务需求,选择不同层数、不同宽度、不同激活函数及其他超参数,经过反复训练和验证,选出表现最优的组合。这个过程不仅耗时且高度依赖计算资源,往往需要大量的训练尝试才能找到合适的架构,这种现象在大规模模型训练中尤为明显。 针对这一问题,神经架构搜索(NAS)逐渐成为研究的热点。NAS利用自动化算法,通过搜索算法在架构空间中寻找表现最优的组合,从而减少人为手工设计成本。NAS方法包括基于强化学习的方法、进化算法以及梯度优化方法,它们能够在给定的搜索空间中自动探索有效的架构,使得模型设计过程更加系统化和高效。然而,NAS本身也面临计算代价高昂的问题,尤其是当搜索空间非常庞大时,需要消耗大量的计算资源才能完成有效搜索。
除了NAS,近年来研究者们试图从理论层面揭示神经网络架构的优劣。深度学习理论的进步使得我们开始理解不同架构在表达能力、优化难度和泛化性能之间的权衡。例如,网络的深度和宽度会影响模型的拟合能力和训练稳定性。过深的网络可能导致梯度消失或爆炸问题,而过浅或过窄的网络又可能无法充分捕捉数据的复杂特征。此外,批归一化、残差连接等技术的引入极大改善了训练深层网络的难度。理论研究也强调了架构设计中应该考虑的因素,如避免过拟合、提升模型鲁棒性和计算效率等。
同时,神经网络架构中的“层叠”设计并非单纯越多越好。堆叠过多层次可能带来性能退化,且影响模型的可训练性和泛化能力。相反,合理的层设计和连接方式,比如跳跃连接,能够帮助信息更好地流动,避免训练中的瓶颈。实际应用中,设计架构还需根据具体任务和数据集进行调整,以平衡复杂度和性能。 如何在训练前判断某个架构优劣,成为当前研究的一个难点。虽然理论研究提供了框架和指导原则,但纯理论难以涵盖所有复杂多变的现实因素。
机器学习领域内越来越多尝试结合理论与数据驱动的方法,通过分析模型的训练曲线、梯度动态、特征表示等指标,预测模型潜力和最终表现。这些方法有助于减少不必要的训练尝试,提升架构设计效率。 此外,计算资源丰富的团队由于能够进行更多次的训练尝试,确实在寻找最优架构上具备优势。这也在一定程度上促进了科研资源、硬件算力、算法优化之间的竞争。云计算、分布式训练技术的普及降低了训练试验的门槛,也推动了更多创新架构的诞生。 未来神经网络架构的设计趋势,可能将更加注重跨学科融合。
结合神经科学、统计学、优化理论以及自动化工具,设计框架将趋于智能化和自适应化。元学习和强化学习技术的结合,赋予网络架构设计“学习设计架构”的能力,大幅缩短实验周期,提升自动化水平。此外,对于特定行业的应用,如医疗、自动驾驶、语音识别,定制化架构也将成为主流趋势,针对具体需求优化网络设计,提高实际应用价值。 总结来看,目前获得最优神经网络架构尚无单一确定路径。传统经验试验、神经架构搜索、理论分析及自动化探索工具共同构成多元化的探索体系。虽然叠加层数和参数调整仍然是常见策略,但通过自动化工具和理论引导,设计过程正逐步成熟和系统化。
未来在计算资源不断丰富以及算法智能化提升的推动下,设计高效、精确和适配性强的网络架构将成为可能,推动人工智能领域迈上新的台阶。