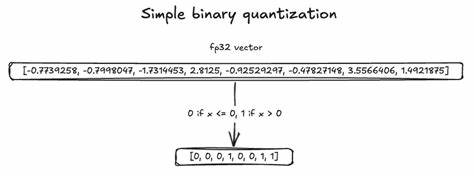
在信息爆炸的时代,如何快速准确地从海量数据中检索相关内容成为技术发展的核心难题之一。二进制向量搜索因其高效的编码和计算特性被广泛应用于近似最近邻搜索(Approximate Nearest Neighbor,ANN)、图像识别、自然语言处理等领域。为了满足企业级应用对检索速度和吞吐量的严苛要求,TopK团队通过深入研究底层指令集,采用ARM NEON技术将二进制向量搜索性能推向新高,达到了惊人的350GB每秒吞吐率。二进制向量搜索的核心在于计算向量之间的汉明距离,即测量两个二进制向量的比特差异数量。这一指标是衡量相似度的重要手段,具备简单快速的计算特性。然而,在面对数百万乃至数十亿级规模的数据时,传统的逐字节计算方法不仅性能受限,而且难以满足高并发场景下的响应需求。
TopK起初采用了Rust语言中的基础实现,通过对两个字节切片执行按位异或(XOR)操作,并累计汉明重量(count_ones),实现汉明距离计算。尽管该方法因其简洁和移植性获得一定认可,但由于缺乏硬件向量化支持,计算效率仍存在提升空间。为了突破性能瓶颈,团队将目光投向了ARM架构下的NEON指令集,这是一套针对SIMD(单指令多数据)计算设计的高效向量指令集,能够同时处理128位寄存器数据,极大提高数据处理并行度。首个基于NEON的实现便表现不凡。通过每次加载16字节数据,执行按位异或,再利用vcntq_u8进行并行汉明重量统计,最后通过水平累加vaddvq_u8将结果汇总。该方案在单线程下实现了近2倍的吞吐增加,多线程亦提升约1.5倍,展现出硬件加速的巨大潜力。
尽管性能提升明显,但开发团队意识到传统累加器单一依赖造成指令执行流水线存在瓶颈。为此,他们引入了指令级并行性(Instruction Level Parallelism,ILP),利用两个累加器并行处理数据流,有效打破依存关系,提升流水线并行度,进一步减少处理延迟。具体实现中,32字节数据分为两段,分别进入两个独立累加器,配合ARM NEON的并行指令完成计算。该方法不仅提升了多线程环境下的吞吐,还减小了存储载入与写回的执行阻塞,成为性能优化的新典范。除了高度优化的数据流分配,考虑到多数向量具有固定长度(如384位至1536位),团队进一步利用这一特性,完全展开循环,将所有计算路径“展开”成静态结构。此举极大减少了控制流程中的分支预测压力,编译器更加精准地安排寄存器使用和指令调度,从而使处理效率迈上一个新台阶。
终极版本针对1024位二进制向量做了专项优化,加载4个32字节块,多个累加器并行累积汉明重量,最后利用多级水平求和指令计算总和。通过矩阵式展开和内存对齐实现了超高吞吐率,单线程峰值达到了62.65亿样本每秒,多线程最高可达到近350GB每秒的数据处理速度。如此性能表现在对亿级数据规模的快速搜索场景尤为重要,使得TopK的检索引擎响应更低延时,资源利用更高效,极大提升了整体系统的性价比。ARM NEON的这些优化技术不仅在实验室表现优异,也为实际生产环境提供了有力的技术保障。通过深入利用指令级并行和数据路径优化,结合面向特定问题(固定向量长度)的循环展开策略,TopK成功将硬件潜力充分激发,实现了行业领先的检索能力。对于企业而言,这意味着能够以更低的硬件投入支持更大规模和更高频次的检索任务,从而应对不断增长的数据场景,提升用户体验。
此次优化背后的技术核心在于对底层指令集的深入理解和精细调度,这也为AI时代的搜索引擎研发提供了宝贵经验。未来,随着ARM架构持续演进和指令集扩展,结合机器学习算法的智能调度与硬件加速,二进制向量搜索将在更多应用领域发挥关键作用。从云端服务、大规模推荐系统到边缘计算设备,其高效、低功耗的特点将得到广泛认可和应用。TopK团队欢迎有志于挑战极限性能、热衷低层优化的专业人才加入,共同推动AI原生搜索引擎技术的不断突破。总之,基于ARM NEON指令集进行的深度优化标志着二进制向量搜索技术迈入一个新的高速发展阶段。通过充分利用硬件并行能力和针对性软件架构设计,TopK实现了单机每秒350GB的数据处理速度,带来了前所未有的检索效率,这不仅加速了人工智能检索应用的落地,也为行业树立了技术标杆。
未来,更多细粒度的硬件优化以及跨平台的适配策略必将推动搜索引擎技术持续创新,引领智能信息检索的新潮流。