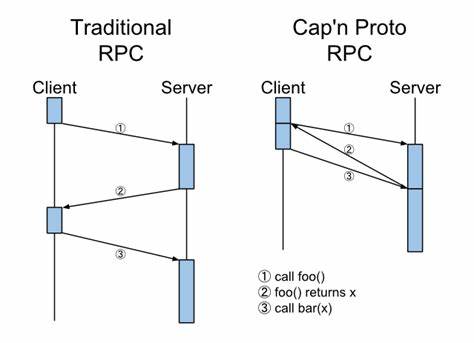
在现代Web开发中,Django因其强大的ORM功能和简洁的设计被广泛采用。然而,当应用面对海量数据读取时,开发者常会遇到查询速度缓慢和内存消耗过高的问题。许多人习惯使用only()方法限制查询字段,希望减少数据库负担和内存使用,但实际效果可能并不理想。相较之下,values()在处理大型只读数据集时,展现出惊人的性能优势。理解两者的差异及合理应用,能帮助开发者极大提升Django应用的查询效率和资源利用率。 Django ORM的核心在于将数据库查询抽象为Python对象,方便开发者操作数据模型。
当使用only()方法时,Django依然实例化模型对象,只是限制加载指定字段,避免加载不需要的字段以节省资源。理论上,这应当提升性能,但在涉及关联模型且查询量庞大时,only()仍会加载完整模型实例,包括通过select_related()预加载的相关模型对象,这就产生了额外的Python处理开销和更高的内存占用。例如查询几十万条图书记录,并使用select_related()关联作者和出版社信息,使用only()分字段限定读取虽然减少了SQL列数,但Django依然为每条记录构造完整模型实例,导致巨大的Python层内存消耗和缓慢的查询响应。 相比之下,values()返回的是字典列表,且不进行任何模型实例化。它直接将数据库查询结果映射成纯粹数据结构,省去了ORM层模型构造的成本。对于只读场景,特别是API输出、报表导出等,大批量数据只需字段数据而无需操作对象行为时,values()显得更加轻量和高效。
实际测试显示,将only()切换成values()后,查询速度可提升至原来的十分之一,内存占用降低超过70%。 这种性能差异的根由在于模型实例化的成本与Python解释器的对象管理开销。Django的装饰方法和属性访问机制保证了ORM的易用性,但也带来了不可忽视的运行时开销。每个模型对象都绑定了字段描述、方法、模型关联信息,而values()省略了一切,只暴露简单键值对,极大减少了内存碎片化和垃圾回收压力。 具体实现中,开发者应根据业务场景选择合适方式。当需要操作模型对象方法、调用自定义属性或者动态处理关联对象时,only()依旧有用武之地,保障代码的可读性和维护性。
但对于明确只需要数据字段并追求极致性能的场景,一定要优先尝试values()配合F表达式指明关联字段的别名。这样不仅提升性能,还方便结果变量的直接调用和序列化。 此外,values()结合annotate()、aggregate()等查询表达式,可以灵活完成复杂数据统计和字段计算,满足不同查询需求。通过合理设计数据库索引和优化查询条件,可以配合values()释放数据库和Python的最大潜力,实现前端响应速度和用户体验的双重提升。 从实际案例来看,一家公司在处理约24万条图书数据时,原有查询使用select_related()和only()组合,耗时超过25秒且内存占用较高。将逻辑改为values()后,查询时间降至2秒内,内存占用骤降至原先的30%。
这一优化不仅缓解了服务器压力,也明显提升了用户操作的流畅度。此实例充分说明了Django ORM选择正确方法对于生产环境的重要性。 综上,熟悉Django ORM的底层工作机制,理解only()和values()的实际区别,是提升大型数据库查询性能的关键。values()在减少Python层面开销、加快处理速度、降低内存需求方面有显著优势,尤其适合只读广泛数据展现。掌握其使用方法,并合理结合关联模型字段查询技巧,可以极大优化应用响应效率,提升整体服务质量。 未来,随着数据量不断扩大和业务复杂度增加,Django开发者更需要关注ORM性能调优细节。
通过关注查询返回数据结构及其处理成本,结合数据库层索引优化和缓存机制,能够构建更具扩展性和高效性的系统架构,保障业务稳定运行和用户体验持续提升。 愿每位使用Django的开发者在优化查询性能时,都能巧用values()带来的轻量与高速,让其应用变得更加健壮、敏捷、令人满意。不断探索与实践,是成长为优秀开发者的必由之路。优化查询不仅是技术挑战,更是用户价值的体现,值得投入时间与精力去深耕细作。